Learning Paths
Last Updated: March 31, 2026 at 12:30
What Are Authentication Tokens and How Do They Work
Tokens as claims carriers, opaque vs self-contained tokens, and the risks of replay and leakage
A single leaked token once brought down a billion-dollar company — because the developer who committed it didn't understand what a token truly is. Authentication tokens are bearer instruments: whoever holds them is presumed authorized, making them both the currency of trust in modern systems and a massive security liability. This article breaks down the fundamental distinction between opaque tokens (random pointers requiring server-side storage) and self-contained tokens (cryptographically signed claims packages like JWTs), then walks through the real-world risks of replay attacks, token leakage, and the common misuse patterns that turn tokens into vulnerabilities. By the end, you'll understand not just how tokens work, but how to store them, scope them, expire them, and protect them as if your entire system depended on it — because it does
A Cautionary Tale: The Token That Brought Down a Billion-Dollar Company
Consider a breach that exposed millions of user records at a major technology company. The attack was not sophisticated. There was no zero-day exploit, no nation-state actor, no elaborate social engineering campaign. The attacker simply found a single authentication token in a public GitHub repository — a token that a developer had accidentally committed with a routine git push.
That token granted the attacker full access to the company's internal infrastructure. Not one service. Everything. The token had been issued with the broadest possible permissions and no expiration. It was, in effect, a master key to the kingdom.
The breach cost the company hundreds of millions of dollars. The developer who committed the token had done nothing malicious. They simply did not understand what an authentication token truly is — and how dangerous a poorly managed token can become.
This article examines authentication tokens: what they are, what they contain, how they work, and most critically, how they can be misused, leaked, and replayed in ways that compromise entire systems. Understanding tokens means understanding the currency of trust in modern software — and learning to protect it.
Part One: What Is an Authentication Token?
An authentication token is a piece of data that proves a user's identity and authorizes access to a system, without requiring the user to re-enter their credentials on every request.
That's the technical definition. But think of them as bearer instruments.
A bearer instrument is something whose holder is presumed to be its rightful owner. Physical cash is a bearer instrument. If you have a $20 bill in your hand, you are presumed to own that $20. There's no registry of who owns which bill. The bill itself is the proof of ownership.
Authentication tokens work the same way. If you possess a valid token, the system assumes you are the legitimate user. The token doesn't ask for ID. It doesn't check your face. It simply says: whoever holds this is authorized.
This is what makes tokens convenient. And this is what makes tokens dangerous.
Part Two: Tokens as Claims Carriers
Every token carries claims. A claim is a statement about the user or the token itself. Think of claims as the "payload" of the token — the information that tells the system who you are and what you're allowed to do.
When a token is transmitted, it appears as a single, opaque string. Here's what a real JWT looks like on the wire:
That single string contains three parts — header, payload, and signature — all encoded and concatenated with dots. The payload is the part that carries the claims. When decoded, those claims become readable:
The signature appended to the end is what makes this token trustworthy. It is created by taking the header and payload, then applying a cryptographic signing algorithm (such as HMAC with a secret key or RSA with a private key). The signature serves a critical purpose: anyone who tries to modify the claims — changing the user ID, elevating their role, extending the expiration — would break the signature, and the server would reject the token as invalid.
(We will dive deeply into how cryptographic signatures work in Phase 2 of this series, covering the algorithms, key management, and implementation details that make signatures secure.)
There are five categories of claims you'll encounter in practice.
Identity claims establish who the user is: user_id: 12345 or email: [email protected].
Authentication claims record when and how the user proved their identity: auth_time: 1700000000.
Authorization claims define what the user can do: role: admin or permissions: ["read","write"].
Context claims capture where and how the user authenticated: ip_address: 192.168.1.1 or device_id: abc123.
Token metadata claims describe the token itself: when it expires (exp), when it was issued (iat), and a unique identifier to distinguish it from other tokens (jti).
Every claim is a statement of fact. The system trusts these statements because the token is cryptographically signed. But here's the critical point: the system only trusts the claims if it trusts the token's origin and integrity.
If an attacker can forge a token, they can forge claims. If an attacker can steal a token, they inherit all its claims.
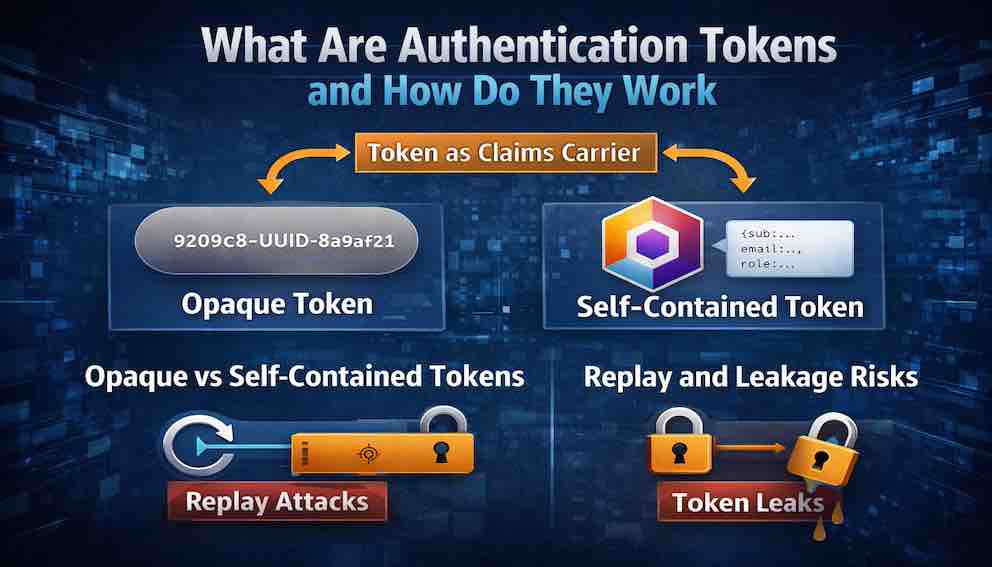
Part Three: Opaque Tokens vs Self-Contained Tokens
There are two fundamentally different ways to build authentication tokens. This distinction determines how tokens behave, how they scale, and — critically — how they can be revoked.
Opaque Tokens
An opaque token is a random string that contains no information about the user. It's called "opaque" because you cannot look at it and understand anything about what it represents. It's a pointer, not a package.
This token means nothing on its own. To use it, the server receives the token, looks it up in a server-side store (a database, Redis, or similar), retrieves the associated user data and claims, and then uses that data to authenticate and authorize the request.
Opaque tokens store all claims server-side. The token itself is small — just a random string, typically 32 to 256 bits — and the client learns nothing from holding it. The decisive advantage is revocation: to invalidate an opaque token, you delete its record from the store, and it dies immediately. The cost is that every request requires a server-side lookup, which adds latency and database load, and the token store must scale with the number of active sessions. Session cookies, API keys, and opaque OAuth bearer tokens all follow this model.
Self-Contained Tokens
A self-contained token embeds all the user information within the token itself, and is cryptographically signed to prevent tampering. The server does not look up anything — it validates the signature and trusts the contents.
Decoded, the payload is directly readable — base64 is not encryption. This is a point many developers miss: a JWT is signed, not secret.
The decisive advantage of self-contained tokens is statelessness: no database lookup on every request, horizontal scaling without shared session storage, and portability across services (any service holding the verification key can validate the token independently). The cost is revocation. Because no server-side record exists, you cannot simply delete a token to kill it. It remains valid until its exp claim is reached — unless you build a revocation blacklist, which reintroduces exactly the server-side state you were trying to avoid.
JWTs, PASETO, and Branca tokens follow this model.
The Core Trade-Off
One sentence captures the distinction: opaque tokens give you control at the cost of state; self-contained tokens give you statelessness at the cost of control.
Neither is universally better. The right choice depends on your revocation requirements, your scaling needs, and how many services need to validate the token independently.
Part Four: Where Tokens Come From
Tokens are issued by a trusted authority — your authentication server or identity provider. The issuance flow is where trust is first established:
- The user proves their identity (password, MFA, biometrics)
- The authentication server verifies the credentials
- The authentication server creates a token
- The token is returned to the client
- The client stores the token and presents it on subsequent requests
The critical security property here is that the token originates from an authority the system trusts. For opaque tokens, trust comes from the token's existence in the server-side store. For self-contained tokens, trust comes from the cryptographic signature.
The issuer defines the trust boundary. A token issued by one service should not be accepted by another service unless there is an explicit trust relationship — shared secrets, a federation protocol, or an OIDC provider both services recognize.
A note on token types in modern systems: you will often encounter access tokens (authorizing actions), ID tokens (asserting identity, as in OpenID Connect), and refresh tokens (exchanged for new access tokens when the old ones expire). These serve different purposes and should be handled differently — more on refresh tokens shortly.
Part Five: Where Tokens Live
Once issued, a token must be stored on the client. Where you store tokens has enormous security implications.
Browser Storage
HttpOnly cookies are only accessible by the server — JavaScript cannot read them. This protects against XSS attacks, where malicious scripts attempt to steal tokens. The trade-off is CSRF vulnerability: because cookies are automatically sent with requests, an attacker can trick a user's browser into making authenticated requests to your service. You mitigate this with SameSite cookie attributes and CSRF tokens.
localStorage and sessionStorage are fully accessible to JavaScript. This means any script running on your page — including third-party scripts, injected ads, or XSS payloads — can read and exfiltrate the token. The trade-off is that they are naturally immune to CSRF, since JavaScript must explicitly include the token in requests.
In-memory (JavaScript variables) offers the best XSS resistance among JavaScript-accessible options, since tokens are not persisted to any inspectable store. The downside is that a page reload destroys the token, requiring re-authentication.
There is no perfect storage location. Each choice trades one risk class for another.
Mobile App Storage
On mobile, always use the platform's secure storage. On iOS, that means the Keychain — hardware-backed, requiring device authentication to access. On Android, use the Keystore system. Never store tokens in plain text files or unprotected shared preferences. A rooted or jailbroken device can expose those easily.
Part Six: How Tokens Travel
Tokens must be sent with every authenticated request. How they travel matters.
The safest standard method is the Authorization header:
This is explicit — the token is never sent automatically — and does not appear in browser history or referrer headers.
Cookies are also acceptable when configured correctly (HttpOnly, Secure, SameSite). Custom headers like X-API-Key follow the same security profile as Authorization headers.
Never send tokens in URLs. A token in a URL is a token waiting to be stolen. URLs appear in browser history, server access logs, proxy logs, CDN logs, and Referer headers sent to third-party sites. Every one of those is a potential leakage vector. No convenience justifies it.
Part Seven: The Risks — Replay and Leakage
Two risks dominate token security: replay attacks and leakage. Understanding both is non-negotiable.
Replay Attacks
A replay attack occurs when an attacker captures a valid token and reuses it to impersonate the legitimate user. The server cannot distinguish the attacker's request from the user's, because the token itself is valid.
Tokens get captured through network sniffing (when traffic is unencrypted), through logs (when a token is accidentally logged in debug output), through browser history (when a token appeared in a URL), and through referrer leakage (when a URL-embedded token is passed to third-party sites).
The mitigations are layered. TLS everywhere is the baseline — encrypt all traffic to prevent interception. Short token lifetimes shrink the window of opportunity: a token valid for five minutes is far less useful to an attacker than one valid for a week. Token binding ties a token to specific client properties (IP address, TLS session) so that the token becomes invalid when presented from a different context. One-time-use tokens invalidate a token after its first use — very strong, but requires server-side state. Replay detection tracks used token IDs (jti claims) in a short-lived cache, rejecting any token whose ID has already been seen.
Token Leakage
Leakage is when a token is exposed to unauthorized parties through means other than active interception. Leakage is often accidental — and more common than targeted attacks.
The most frequent vectors: a developer commits a .env file or config file containing a token to a public repository; console.log(token) left in production code exposes tokens in browser developer tools; error messages include tokens in stack traces; malicious or compromised third-party JavaScript reads tokens from localStorage; browser extensions with excessive permissions extract stored tokens; a stolen device gives physical access to whatever is stored on it.
The mitigations: never log tokens (strip them at the application level); use HttpOnly cookies to prevent JavaScript access; set short lifetimes so leaked tokens expire quickly; restrict scope so a leaked token cannot do everything; use secret scanning pre-commit hooks to catch secrets before they reach version control; and never, ever hardcode tokens in source code — use environment variables or a secrets manager.
Part Eight: A Critical Vulnerability — JWT Algorithm Confusion
This section deserves its own space because it is responsible for a class of real-world attacks that are both elegant and devastating.
JWTs specify their signing algorithm in the token header:
Two attacks exploit this field.
The alg:none attack. Some JWT libraries, when they see "alg": "none" in the header, will accept the token as valid without verifying any signature at all. An attacker crafts a token with "alg": "none", sets any claims they want, provides no signature — and a vulnerable library accepts it as authentic. This is not theoretical. Real libraries shipped with this behavior. The fix: always explicitly specify which algorithms your server accepts, and reject everything else.
Algorithm confusion (RS256 to HS256). When a server uses an asymmetric algorithm like RS256, it signs with a private key and verifies with a public key. The public key is, by definition, public. If a vulnerable library accepts both RS256 and HS256 (HMAC with a shared secret), an attacker can take the server's public key, forge a token signed with HS256 using that public key as the HMAC secret, and the library will accept it — because it verified the HMAC signature using the public key, which it knows. The fix: pin your JWT library to a single expected algorithm, and never accept a different one.
These are not edge cases. They are documented attacks with CVEs attached to real libraries. Always verify signatures. Always specify the algorithm explicitly. On every request. No exceptions.
Part Nine: Token Scope — Least Privilege in Practice
One of the most common token mistakes is issuing tokens with overly broad permissions. A token that can do everything is a single point of failure for everything.
Token scope is the set of actions or resources a token is authorized to access. In OAuth, scopes are explicit strings:
Each scope is a specific permission. A leaked token with read:account can read account data. A leaked token with admin:all can destroy the system.
Scopes can be narrowed along several dimensions.
Resource scope limits what data is accessible — only the user's own records, not all records.
Action scope limits what operations are permitted — read but not write, write but not delete.
Time scope limits when the token is valid — only during business hours, or for the next five minutes.
Network scope limits where the token can be used — only from specific IP ranges or geographic regions.
The rule is simple: issue tokens with the narrowest possible scope for their intended use. A mobile app token should not have admin permissions. A background job token should not be able to delete data. A read-only reporting integration should not have write access. Scope creep is real, it accumulates quietly, and it matters enormously when something goes wrong.
Part Ten: Token Lifetime and the Refresh Token Pattern
Every token should expire. The question is when.
Very short lifetimes — minutes — minimize the window of opportunity if a token is stolen, but require frequent re-authentication, which frustrates users and increases server load. Very long lifetimes — days, months, or never — are convenient but catastrophic if a token leaks. A token that never expires is a permanent backdoor.
The practical resolution is the access token / refresh token pattern.
Access tokens are short-lived — typically five to fifteen minutes. They are presented with every API request. When one expires, the client uses a separate, long-lived refresh token (valid for days or months) to obtain a new access token without asking the user to log in again.
The security advantage is layered. The short-lived access token limits replay attack windows. The refresh token lives in a more protected location (typically an HttpOnly cookie or a secure store), is only sent to the authorization server, and can be revoked at the server level. When a user logs out or a compromise is detected, you revoke the refresh token — all new access tokens stop being issued, and the user's access ends within minutes as existing access tokens expire.
A complementary pattern is refresh token rotation: every time a refresh token is used to get a new access token, the old refresh token is invalidated and a new one is issued. If a stolen refresh token is ever used, the legitimate user's next request will fail (their token was already rotated), and you have a signal of compromise.
Part Eleven: Token Revocation — How Tokens Die
Tokens end in one of three ways.
Expiration is the natural end state. The token reaches its exp value and is no longer accepted. For self-contained tokens, this requires no server-side action. The downside is that a compromised token remains valid until it expires — which matters when lifetimes are long.
Logout is intentional termination. For opaque tokens, the server deletes the token record from the session store, and the token dies immediately. For self-contained tokens, the client discards the token locally — but unless you maintain a revocation blacklist, the token itself remains cryptographically valid until expiration.
Revocation is forced termination before expiration. You need this when a password changes, suspicious activity is detected, an account is suspended, or a token is known to be compromised. For opaque tokens, deletion is immediate and clean. For self-contained tokens, you maintain a blacklist of revoked jti values, checked on every request. This reintroduces server-side state — the exact thing self-contained tokens were designed to avoid — but if you need reliable revocation, it is the price.
The practical takeaway: if your system absolutely requires immediate revocation, opaque tokens or the access/refresh pattern with short access token lifetimes are better choices than long-lived JWTs.
Part Twelve: Common Token Misuse Patterns
These are the mistakes that appear repeatedly in production systems.
Tokens in URLs. A token in a query parameter appears in browser history, server logs, proxy caches, and Referer headers sent to every third-party resource on the page. There is no justification for this pattern. Use Authorization headers or cookies.
Excessive scope. A token for reading user profiles also has delete permissions. An integration token for a read-only dashboard also has write access. Scope creep is dangerous because the blast radius of a leak grows proportionally with what the token can do. Audit token permissions regularly.
No expiration. Tokens that never expire are permanent backdoors. Every token should have an exp claim. For long-lived API keys where expiration is impractical, implement rotation policies and a revocation mechanism.
Hardcoded tokens in source code. This is how the opening story happened. Source code is copied, shared, pushed to repositories, and often ends up public. Use environment variables and secrets managers. Run secret scanning tools as part of your CI pipeline.
Sensitive data in token payloads. A JWT payload is base64-encoded, not encrypted. Anyone who captures the token can decode and read it. Credit card numbers, social security numbers, passwords, and similar data have no business in a token payload. If you need the token to carry sensitive data, use JWE (JSON Web Encryption) or keep that data server-side with an opaque token.
Missing or partial signature verification. Parsing a JWT and using its claims without verifying the signature is the same as accepting a letter of recommendation without checking whether it's forged. Combine this with the algorithm confusion vulnerabilities described earlier, and you have a recipe for complete authentication bypass. Verify signatures on every request, pin your expected algorithm, and reject anything that doesn't match.
Trusting client-supplied token algorithms. Related to the above: never let the client dictate how their token should be verified. Specify the algorithm server-side, explicitly, and ignore whatever the token header claims.
Part Thirteen: Where This Fits in the Unbroken Chain
Recall the Unbroken Chain from Article 1. Tokens are the mechanism that carries identity from Layer 3 (Backend) through every subsequent request.
The token is the thread that connects authentication to every action the user takes. If the token is compromised, every link after it is compromised. This is why token security matters so much — not because tokens are complicated, but because they are the single point of continuity in the authentication chain.
Closing: The Master Key
Let us return to the developer who committed that token to GitHub. They did not intend to create a security disaster; they simply did not understand what a token truly represents. A token is not merely a string — it is a bearer instrument, a piece of authority made tangible that grants whoever possesses it the ability to act as someone else without further authentication. Tokens carry claims: statements about identity (who the user is), authorization (what they can do), and metadata (when they expire, when they were issued, and a unique identifier). In self-contained tokens like JWTs, these claims are embedded directly in the token and cryptographically signed to prevent tampering; in opaque tokens, the token is a pointer to server-side storage where the claims reside. Proper token use demands secure storage (HttpOnly cookies for web, Keychain or Keystore for mobile), narrow scoping (minimum permissions for the intended use), aggressive expiration (short lifetimes with revocable refresh tokens), thorough verification (signature validation on every request with pinned algorithms), and immediate revocation when compromise is suspected. Yet tokens carry inherent weaknesses: their bearer nature means anyone holding them is trusted; they can leak through logs, URLs, or source code; captured tokens can be replayed; self-contained tokens lack built-in revocation; and client-side storage risks exposure to malicious scripts. A stolen password still requires a login flow, but a stolen token is already past the door — which is why tokens must be handled with the same care as the user's credentials, and why understanding what a token really is transforms token handling from a checklist into a coherent security discipline.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.