Learning Paths
Last Updated: May 6, 2026 at 10:30
CAP Theorem in Microservices: Real-World Trade-offs, Examples, and Why Systems Fail at Scale
Why your distributed system will eventually lie to you — and how to decide which lie is acceptable
CAP theorem isn't just academic theory — it's the hidden force behind every timeout, retry, and data inconsistency in your microservices architecture. In a distributed system, network failures aren't edge cases — they're the steady state. Understanding CAP means shifting your thinking from "how do we prevent failure?" to "which failure are we willing to design for?" This guide explains CAP from the ground up, with real-world examples, so you can make intentional trade-offs instead of accidental ones.
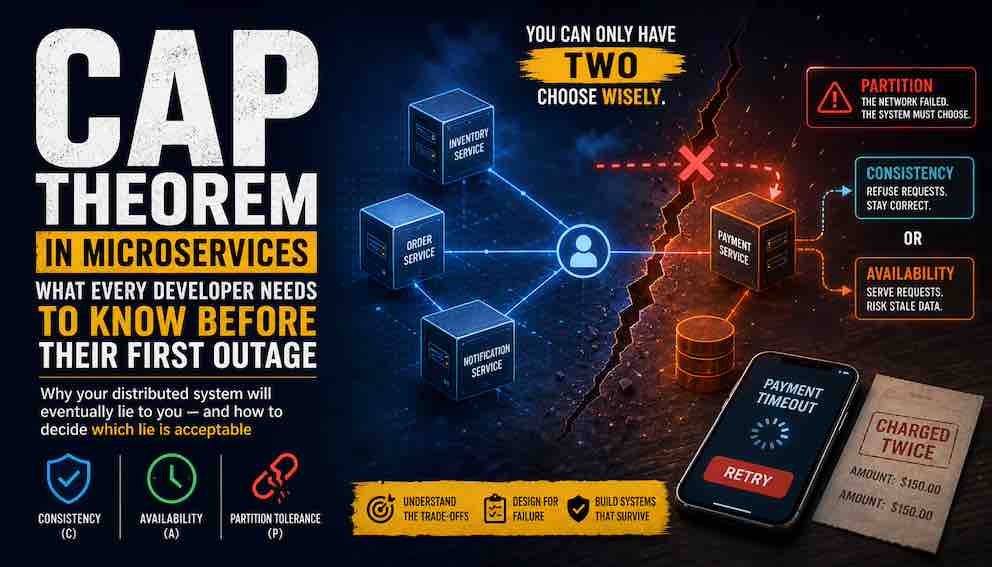
The Double Charge That Shouldn't Have Happened
It's 2 AM. Your phone buzzes. A customer has been charged twice for the same order, and your logs show nothing wrong. Both services completed successfully. Both database writes committed cleanly. By every metric your system tracks, everything worked.
And yet, the customer was charged twice.
This isn't a bug you can fix with a hotpatch. It's a fundamental property of distributed systems — one that has a name, a theorem, and decades of engineering thought behind it. That theorem is CAP, and once you understand it, you'll stop saying "that shouldn't happen" and start designing systems where you consciously choose what breaks, and how.
What Even Is a Distributed System?
Before we get into CAP, it helps to understand what we mean by a distributed system, because the answer is more mundane than it sounds.
A distributed system is any system where multiple computers need to coordinate over a network to complete a task.
That's it. If your payment service makes an HTTP call to an inventory service, you have a distributed system. If your backend reads from a database on a different machine, you have a distributed system. The moment you have two processes on two machines that need to agree on something, you have entered distributed systems territory — with all of its consequences.
In the monolith era, most applications ran on a single machine, and the database was the single source of truth. If the server went down, the whole system went down — painful, but at least consistent in its failure. There was one truth, or no truth. Never two.
Microservices changed everything. Now a single user action might touch five services, three databases, and a message queue — all communicating over a network that can and will fail. This is when CAP stops being theory and starts being your problem.
Here's the full replacement — one unified section that builds from the ground up, introduces the theorem directly, and flows into the partition examples without feeling like three separate pieces stitched together:
What CAP Theorem Actually Says
If you've spent any time reading about distributed systems, you've probably encountered CAP theorem—usually in a diagram with three overlapping circles labeled Consistency, Availability, and Partition Tolerance, accompanied by the memorable advice to "pick two."
That advice is a good starting point. But it's incomplete.
And for engineers building microservices, acting on an incomplete understanding leads to decisions that seem right on paper but fail quietly in production.
So let's build it from scratch. No shortcuts. No "pick two." Just the actual theorem, what it means, and—most importantly—what it forces you to decide when your system is already under stress.
Start With the Problem, Not the Definition
The best way to understand CAP is not to memorize three properties. It's to see the problem those properties are trying to describe.
Imagine three services: Payment, Order, and Inventory.
The Payment service processes a request. The Order service waits for a response. But the response never arrives. A packet is dropped. A timeout fires.
From Order's perspective, Payment never answered.
Payment thinks the request succeeded. Order thinks it failed.
Both are correct—from where they stand.
What just happened?
A network partition is a break in communication between nodes that are otherwise running perfectly. The services didn't crash. The code didn't bug out. They just lost the ability to talk to each other.
Payment and Order are now on opposite sides of a silent split. That is a partition. Not a dramatic outage. Not a system crash. Just a quiet break in communication between two processes that are otherwise healthy.
Now Order has exactly two options.
Option one: Wait. Refuse to proceed until it knows what really happened. This protects correctness. But the request hangs or fails.
Option two: Move forward. Respond anyway, based on incomplete information. This keeps the system responsive. But it risks being wrong.
Order cannot safely do both.
That tension—correctness versus responsiveness when communication breaks—is what CAP theorem is actually describing.
The Theorem, Directly Stated
The CAP theorem was introduced by Eric Brewer in 2000 and formally proven by Gilbert and Lynch in 2002.
Here is what it says: When a network partition occurs, a distributed system cannot guarantee both Consistency and Availability at the same time.
Remember Payment and Order from the last section? Payment succeeded. Order timed out. They couldn't talk to each other. That was the partition.
Now apply the theorem to that moment.
Order has two choices, but it cannot do both:
- Keep the data correct (Consistency) – Order waits until it knows what Payment really did. But the user's request hangs or fails.
- Keep the system responsive (Availability) – Order answers immediately. But the answer might be wrong or based on stale information.
That's the trade-off. In that exact moment when communication breaks, Order has to pick one. It cannot give the user a correct response and an immediate response at the same time.
What the theorem does not say:
- It does not say you must permanently sacrifice one property forever.
- It does not say your system is broken when the network is healthy.
- It does not say you cannot have both Consistency and Availability most of the time.
It only says this: when communication breaks, correctness and responsiveness cannot both be guaranteed. One of them has to give.
CAP is not a constraint you work around. It is the set of trade-offs your system is already making—whether you acknowledge them or not.
What the Three Properties Actually Mean
With that foundation in place, the three terms become precise rather than abstract.
Let's define each one carefully.
Consistency (C) – in the specific context of CAP theorem – means strong consistency. Every read receives the most recent write, or an error. If you update a user's balance to £500, every subsequent read from anywhere in the system returns £500. There are no "eventual" caveats. If the system cannot guarantee that – because of a partition, a lagging replica, or any other reason – it refuses to answer. An error is better than a lie.
(Other forms of consistency exist – eventual, causal, monotonic – but CAP is talking about this strong form.)
Availability (A) means every request receives a response. Not necessarily the most recent data – but a response. The system does not hang, and it does not refuse to answer. In practice, this means the system answers from whatever information it can reach right now. That information might be stale. But it is not arbitrary, and it is not a guess.
The distinction matters: Consistency returns an error when uncertain. Availability returns a response – and accepts the risk that the response may be out of date.
Partition Tolerance (P) means the system continues operating even when messages between nodes are lost or delayed. A partition-tolerant system is designed for the reality that networks break. It does not freeze, crash, or wait for healing. It keeps processing requests on each side of the split using whatever information is still available.
Back to our Payment and Order example:
- A Consistency-first system: Order waits. It refuses to confirm anything until it knows what Payment really did. The user sees a delay or an error.
- An Availability-first system: Order answers immediately. It assumes Payment failed, or assumes it succeeded – and accepts that the assumption might be wrong.
- Partition Tolerance is not a choice. It is the background reality that Payment and Order lost contact in the first place.
Why Partition Tolerance Is Not Optional
CAP is usually taught as a pick-two menu: Consistency and Availability, Consistency and Partition Tolerance, or Availability and Partition Tolerance. This framing sounds tidy. It is also misleading, and In 2012, Eric Brewer himself acknowledged it.
Partition tolerance is not a feature you opt into. It is a condition you accept because networks are unreliable by nature. Packets are dropped. Services pause under load. Availability zones have brief hiccups. These are not rare catastrophes — they are the normal behavior of distributed systems at any meaningful scale.
If your system communicates over a network — and it does — partitions(messages between nodes are lost or delayed) will happen. So the question is never "do we need partition tolerance?" The question is: when a partition happens, what do you give up?
You are left with one real decision. Do you keep serving requests and risk returning stale or incorrect data — choosing Availability? Or do you stop serving requests until the partition heals and correctness can be guaranteed — choosing Consistency?
Everything else in distributed systems design flows from how you answer that question.
What Partitions Actually Look Like
Partitions don't look like disasters. They look like timeouts.
Your order service calls your payment service over HTTP. The payment service receives the request, processes the payment, but the response packet gets lost on the way back. The order service never gets a success confirmation, so after a timeout it assumes failure and retries. Now the payment has been processed twice.
Or your service reads from a database cluster with a primary and two replicas. The primary processes a write. Before that write replicates, a network hiccup makes the primary unreachable. Your service fails over to a replica — which still has the old data. You're now serving stale values, and depending on what your code does with them, the consequences range from a minor display glitch to a financial error.
Neither scenario involves a server going down or an alert firing. Both are partitions. Both force a choice between consistency and availability — whether you've deliberately made that choice or not.
Why Microservices Make CAP Unavoidable
In a monolith, CAP trade-offs are mostly hidden inside your database engine. PostgreSQL with serializable transactions gives you strong consistency. You don't have to think about it much.
In a microservices architecture, those trade-offs move to the surface — into every API call, every timeout configuration, every retry policy, and every message queue you add.
Every service boundary is a potential partition point. The more services you have, the more boundaries you have, and the more often partitions occur. What was once an internal function call is now an HTTP request that can fail, time out, or return a stale cached response.
So what happens when you call another service and don't get a response? You have four options — and the one you choose is your CAP decision.
Assume success and move on. You decide the request probably went through and continue. This keeps your system responsive, but you risk duplicate operations or inconsistent state. This is an Availability bias.
Retry the request. You send it again, hoping the failure was temporary. But if the original request actually succeeded, an unguarded retry creates duplicates. Retrying with an idempotency key makes this safe — without one, you're trading consistency for availability without realising it.
Wait and poll for a result. Deferred consistency. Accept a pending state now, reconcile when the downstream service responds. The most realistic option for operations where neither failure nor assumption is acceptable.
Return a failure and stop. You tell the user "try again later" and surface the error for intervention. This protects correctness but damages user experience and creates operational load. This is a Consistency bias.
None of these is universally right. The correct choice depends on what you're building. A payment system should return a failure. A product catalog might assume success. A notification system should retry — but only with idempotency keys in place.
The danger is not picking one. The danger is assuming you don't have to.
This isn't a criticism of microservices — it's the physics of the architecture. If you're building microservices and haven't thought about CAP, you've already made these choices implicitly. You just won't find out which ones until something breaks at 2 AM.
CAP Is Not a System-Level Decision
Here's something that trips up even experienced engineers: CAP trade-offs are not made once for your entire system. They're made separately for each workflow, each service, and sometimes each individual endpoint.
Consider a typical e-commerce platform. The product catalog might serve from a cache aggressively. A product price that's 30 seconds stale is fine — availability matters more than perfect accuracy here. This is an AP choice. The checkout flow must not double-charge a customer. You'd rather return a "payment is processing, please wait" error than commit a payment twice. This is a CP choice. The recommendation engine can return results from a model last updated an hour ago. No user is harmed by slightly outdated recommendations. AP again.
The same user, in the same session, on the same platform, is being served by services with fundamentally different consistency guarantees. This is fine — ideal, even. What's not fine is applying those trade-offs unintentionally.
A circuit breaker configured too aggressively can start returning stale data under load, turning what you thought was a consistent service into an eventually-consistent one.
Three Real Scenarios, Three Different Answers
Payment Processing — When Correctness Beats Everything
Payment systems almost universally choose consistency over availability. The cost of incorrect data — a double charge, a refunded transaction that wasn't flagged — is higher than the cost of a failed request where the user sees an error and tries again.
Stripe's idempotency keys are a textbook CP design. When you send a payment request with an idempotency key, Stripe detects a duplicate and refuses to process it again — even if the first request appeared to fail on your side. The customer might see a "payment is processing" message, but they won't be charged twice. This is what solving the 2 AM double-charge problem actually looks like: not preventing partitions, but designing for them.
If you're building payment systems, your goal is to make retries safe. An operation is idempotent if doing it multiple times has the same result as doing it once. Think of a light switch: flipping it to "on" when it's already on does nothing. That's what you want from a payment request — processing the same request ten times should have the same outcome as processing it once.
Product Catalog — When Uptime Is the Priority
An e-commerce product page that returns a 503 error costs you a sale. A product page that shows a price from 20 seconds ago costs you... usually nothing. The user adds it to their cart, and by the time they check out, the price is validated again.
This is why product catalogs lean heavily toward availability. Amazon serves product pages from aggressive caches. Netflix serves your homepage from regional caches. These pages might be slightly stale, but they load — which is the most important thing. The design principle here is: reads can tolerate staleness, as long as writes are eventually consistent. The catalog will catch up. A brief inconsistency is invisible to most users.
Notifications — When Duplicates Beat Missing Messages
Email and push notification systems typically choose availability, accepting the risk of duplicate delivery over missed delivery.
Missing a password reset email generates a support ticket. Receiving one twice generates a shrug.
Apache Kafka, one of the most widely used messaging systems, guarantees "at-least-once" delivery by default. This means you might receive the same message more than once, and you have to design your consumers to handle that gracefully. If processing a message twice causes problems, you need to make your processing logic idempotent — checking whether you've already handled this message before doing anything with it.
Idempotency: The Tool That Tames the CAP Trade-off
Idempotency comes up in every distributed systems conversation and understanding it correctly is very important.
An operation is idempotent if you can repeat it multiple times without changing the outcome beyond the first execution. DELETE /users/123 should be idempotent — call it five times, the user gets deleted once. POST /payments is not idempotent by default — call it five times, you get five payments.
In distributed systems, retries are inevitable. Network timeouts happen. Clients resend requests. Systems recover from crashes and replay queued messages. All of this creates a world where the same operation arrives multiple times, and your system needs to handle that gracefully.
Idempotency is how you make retries safe under AP conditions. You're not trying to prevent the duplicate request from arriving — that's a partition problem, and partitions happen. You're ensuring that when it does arrive, it doesn't cause harm.
Common implementation approaches include using a unique request ID or idempotency key that you check before processing (if you've already processed this request ID, return the stored result rather than re-running the operation), using database upserts instead of inserts, and designing state machines where transitions are naturally safe to repeat.
How CAP Shows Up in Your Architecture Without Saying Its Name
CAP doesn't announce itself. It shows up quietly in the decisions you make about protocols, infrastructure, and failure handling.
Synchronous vs. asynchronous communication is a CAP decision. When your service makes a synchronous HTTP call and waits for a response, it's pushing toward consistency — the caller knows the result before moving on. When you publish an event to a message queue and move on without waiting, you're accepting eventual consistency in exchange for not blocking the caller.
Retry policies encode a CAP bet. Retrying a failed request preserves availability but risks duplicate processing — shifting you toward AP. Retrying with an idempotency key preserves consistency while keeping availability reasonable.
Circuit breakers can dynamically flip your system from CP to AP under load. When a circuit breaker opens because a downstream service is slow, it starts returning cached or default values instead of waiting. That's a live switch from consistency to availability. This is often the right call under pressure, but it should be intentional and monitored, not a surprise.
Read replicas are an explicit AP choice. Reads from a replica may be milliseconds behind the primary — usually fine, until it isn't. If you read your own write from a replica before replication completes, you'll see stale data. Many databases offer a "read your own writes" consistency level to handle this specifically.
Caching is an AP mechanism by nature. A cache serves old data to preserve speed and availability. The freshness window is your consistency trade-off. Cache invalidation strategies — like writing through the cache on updates — can shift this toward CP at the cost of performance.
These are not accidental decisions. The most effective engineers recognize them as CAP choices and make them intentionally — not by default.
Beyond CAP: The PACELC Model
CAP describes what happens when a partition occurs. But most of the time, your system is healthy and there is no partition. Does the consistency vs. availability trade-off still matter then?
Yes — and that's what the PACELC model captures.
PACELC says: if there's a Partition, you choose between Availability and Consistency — that's CAP. Else, when the system is running normally, you choose between Latency and Consistency.
Strong consistency requires coordination — nodes have to agree before returning a result. That coordination takes time. If you want the freshest possible data on every read, you pay in latency. If you're willing to accept slightly stale data, you can serve reads faster.
Different systems offer different dials for this trade-off:
- DynamoDB lets you request a strongly consistent read, which always returns the most recent data, or an eventually consistent read, which is faster but may return data that's a fraction of a second behind.
- MongoDB is strongly consistent by default within a single document and within a single replica set, when reading from the primary with the default read concern of "local.". You can relax this for better performance, or increase it to "linearizable" read concern for the strongest guarantee.
- Cassandra lets you configure consistency levels per query — from ONE (fast, may be stale) to ALL (strong, but may fail if any replica is down).
- PostgreSQL with synchronous replication can give you strong consistency, but at the cost of higher write latency.
- Kafka lets you choose between acks=1 (leader confirms, fast) and acks=all (all replicas confirm, stronger but slower).
Neither choice is wrong — they're just different points on the latency/consistency curve. The CAP theorem doesn't forbid strong consistency. It just tells you what you sacrifice (availability or low latency) to get it.
PACELC matters in practice because it shows that even when your system is healthy, consistency has a cost. Acknowledging this helps you make deliberate decisions about where that cost is worth paying, rather than discovering it during a performance review six months later.
Handling Distributed Transactions: The Saga Pattern
One of the hardest problems CAP surfaces in microservices is distributed transactions. In a monolith, you wrap multiple operations in a database transaction — they all succeed or all roll back, atomically. In microservices, you can't do that across service boundaries without introducing heavy coordination that destroys availability and creates brittle coupling.
The most widely adopted alternative is the Saga pattern.
A saga breaks a distributed transaction into a sequence of smaller, local transactions — each fully within a single service. If any step fails, the saga triggers compensating transactions to undo the previous steps.
A concrete example: an order placement saga might run as reserve inventory → charge payment → confirm order. If the payment fails, a compensating transaction releases the reserved inventory. If the order confirmation fails, a compensating transaction refunds the payment and releases inventory. Each step is local, and each has a defined rollback.
Sagas don't eliminate inconsistency — they manage it over time. At any moment during execution, the system might be in a partially complete state — inventory is reserved but payment hasn't processed yet. But eventually, either all steps complete successfully, or all compensating transactions run, and the system reaches a consistent final state.
This is the pragmatic middle ground most production systems land on. It's CP in intent — you're designing toward correctness — without requiring cross-service locking that would make your system fragile and slow.
A Framework for Making CAP Decisions in Design Reviews
By this point, CAP stops being theoretical. It becomes a set of decisions you make — often under pressure, often with incomplete information.
What is the cost of incorrect data? If the answer involves money, legal liability, or physical safety, lean toward consistency. Accept that some requests will fail or be delayed. Make those failures visible and retryable rather than silently proceeding with wrong data.
What is the cost of unavailability? If users see errors and leave, if revenue is directly lost per minute of downtime, lean toward availability. Accept staleness and duplicates. Design the user experience to tolerate them.
How often will this path be retried? In microservices, the answer is always "more than you think." Make every operation idempotent. Design for at-least-once delivery, and ensure that duplicate execution causes no harm.
Does this operation cross service boundaries? If yes, consider whether you need a saga pattern, an idempotency key, or an explicit eventual consistency contract between services.
Are you reading or writing? As a starting heuristic: reads can often tolerate AP(Availability over Consistency), writes usually need CP(Consistency over Availability). Start there and adjust based on actual requirements and what you can measure breaking.
There Is No Perfect System — Only Intentional Trade-offs
CAP theorem doesn't offer a way out. It offers clarity.
Here's what this article has covered:
First, a partition is not a disaster. It's a break in communication — two services that can't talk to each other, even though both are running fine.
Second, when a partition happens, you cannot guarantee both correctness (Consistency) and responsiveness (Availability). You have to choose which one to sacrifice in that moment.
Third, microservices put this choice everywhere — into every API call, every timeout, every retry. What was once hidden inside your database is now in your code.
Fourth, different systems let you choose where you sit on the trade-off. DynamoDB offers strongly consistent reads or eventually consistent reads. MongoDB defaults to strong consistency but lets you tune it. Cassandra lets you set consistency levels per query. None of these choices is wrong. They just prioritize different things — speed or accuracy, availability or correctness.
Fifth, you can start with a simple heuristic: reads can often tolerate stale data. Writes usually need correctness. Then measure. Adjust when you see double charges, stale dashboards, or retry storms.
Every distributed system makes these trade-offs. The only question is whether you make them deliberately or accidentally.
When a request times out and the client retries, you won't say "that shouldn't happen." You'll know what you chose to break. And when it breaks at 2 AM, it will behave exactly as you designed it.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.