Learning Paths
Last Updated: April 27, 2026 at 10:02
The Saga Pattern in Microservices: Why Distributed Transactions Don't Scale — and How to Recover When Things Fail
Why distributed transactions don't scale — and how sagas manage multi-step consistency without central coordination
The saga pattern is a distributed systems technique that breaks a multi-step transaction into a sequence of local operations, each paired with a compensating action that can undo it if a later step fails. Unlike two-phase commit, sagas do not hold locks across services — they accept eventual consistency in exchange for high availability. When a step fails mid-saga, the system executes compensations in reverse order until consistency is restored. The result is a system designed not around how things succeed, but around how they recover when success is no longer possible.
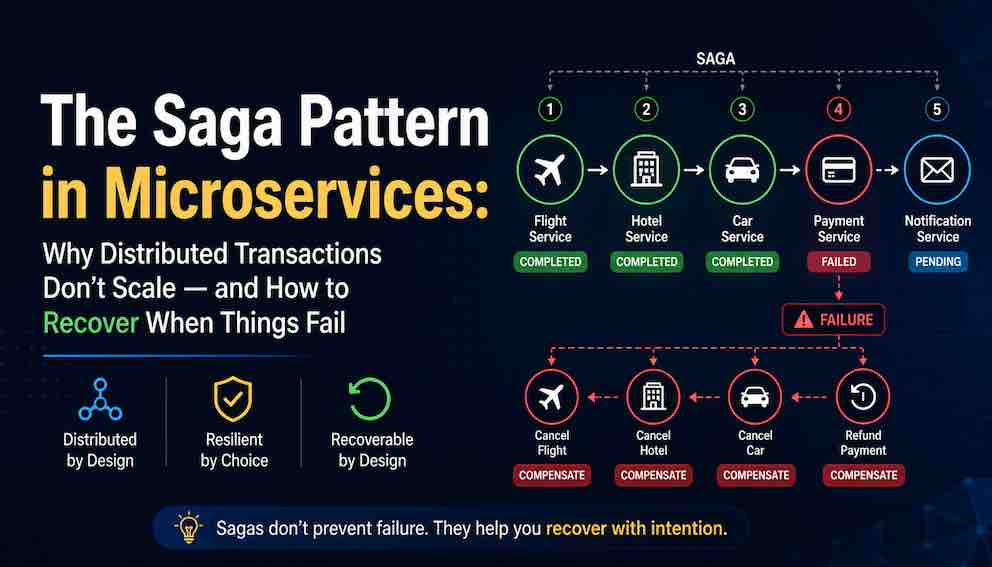
The Problem Sagas Solve
Your system completed three of five steps.
The flight is booked. The hotel is reserved. The car is confirmed.
The fourth step fails — payment declined.
What happens now?
These are not rows in a single database you can flip back with a rollback command. Each reservation lives in a separate service, with its own database, that has already acted on the request. The flight service does not know the hotel exists. The hotel has no idea a car was confirmed. There is no shared transaction spanning all three — and therefore no shared rollback.
The customer has a flight, a hotel, and a car — but no payment. You need to release all three reservations. You must explicitly call each service with a new request: release the seat, release the room, release the car.
Those explicit reversal requests are called compensating transactions. They are not automatic. They are not free. You have to design and build each one deliberately. And they can fail too.
This is the problem sagas solve. Not how to sequence steps when everything works — but how to recover when something fails halfway through a process that cannot be atomically undone.
A saga is not a workflow. It is a failure management system disguised as a workflow.
Most teams design their happy path carefully and treat failure as an edge case. Sagas force you to do the opposite: design your failure path first, and let the happy path follow from it.
Key Concepts to Understand First
Before explaining how sagas work, it helps to define some terms that will come up throughout this article. These are not obscure concepts — they are the building blocks the saga pattern depends on.
Local transaction — A single database operation that is atomic within one service. It either fully succeeds or fully fails, with no partial state. Sagas are built from a chain of local transactions across multiple services.
Compensating transaction — An operation that undoes the business effect of a previous local transaction. This is not a database rollback. It is a new, deliberate action — for example, refunding a payment or releasing a reserved seat. The key point: compensating transactions must be designed by you. They are not automatic.
Eventual consistency — In a single database, when you save something, every part of your system sees it immediately. A saga cannot do that.
When a saga runs, services see updates at different times. The flight service confirms the booking right away. The hotel service gets the request a few seconds later. For that brief window, the two services disagree on whether the trip exists.
That is eventual consistency. The system becomes consistent only after all steps finish.
Idempotency — The property of an operation that makes it safe to run multiple times with the same result. If an operation is idempotent, retrying it after a timeout does not cause duplicate effects. This is essential in distributed systems where you can never be certain a request was received exactly once.
Atomicity — The "all or nothing" guarantee of a database transaction. Either every operation in the transaction succeeds, or none of them do. In a single database, this is easy. Across multiple services with their own databases, it is impossible without coordination mechanisms like sagas or two-phase commit.
With those definitions established, the rest of the article will be considerably easier to follow.
What the Saga Pattern Actually Is
Here is the formal definition: a saga is a sequence of local transactions, where each step has a corresponding compensating action, coordinated to achieve eventual consistency across services.
That is still abstract. Let me break it into its three required parts.
The forward path — The sequence of local transactions that achieve the business goal when everything succeeds. In travel booking, this is: reserve flight → reserve hotel → reserve car → capture payment → send confirmation.
The compensation path — The sequence of compensating actions that undo completed steps when a later step fails. If payment capture fails after flight, hotel, and car are all reserved, compensations release the car, then the hotel, then the flight — in reverse order.
The coordination mechanism — The logic that decides which step to execute next, when to trigger compensations, and how to handle failures in both directions. There are exactly two ways to build this: orchestration, where a central coordinator controls the entire flow and calls each service in sequence; and choreography, where there is no central coordinator and services react to events published by each other. Both approaches can implement the same saga. They differ in where control lives and how failures are traced. The trade-offs between them are covered in detail later in this article.
Without all three parts, you do not have a saga.
It is also worth being clear about what a saga is not. It is not a replacement for a database transaction. It is not a workflow engine. It does not guarantee that every step will eventually succeed. It guarantees that when the system cannot proceed forward, it has a defined path to undo what it has already done.
Why Two-Phase Commit Fails at Scale
To understand why sagas exist, you need to understand what they replaced.
The traditional approach to distributed consistency was two-phase commit (2PC). The idea is straightforward: a coordinator asks all participants "are you ready to commit?" If every participant says yes, the coordinator sends a commit. If any participant says no or does not respond, the coordinator sends a rollback.
The mechanism works, but it has a critical problem. While waiting for all participants to confirm, the coordinator holds locks on every resource involved. If any single service is slow, all other services wait. If any single service is unavailable, the entire transaction is blocked.
In a microservices architecture, this is unacceptable. Services will occasionally be slow. Network calls will occasionally time out. You cannot accept a design where the availability of your entire system equals the availability of its least available component.
This is the core trade-off:
- Two-phase commit trades availability for consistency. All services commit together or none do. But if any service is down, nobody can proceed.
- Sagas trade strong consistency for availability. Services do not hold locks. They execute their local transactions independently. When something fails, the system recovers through compensation.
Neither approach is universally better. Two-phase commit is the right choice when scale is small, latency requirements are tight, and eventual consistency is genuinely unacceptable. Sagas are the right choice when services must remain independently available, and the business domain can tolerate a brief window of inconsistency during recovery.
Most modern distributed systems fall into the second category. That is why sagas exist.
When to Use Sagas
Sagas are not a general-purpose tool. They solve a specific problem: multi-step transactions across independent services where partial completion must be recoverable and eventual consistency is acceptable.
Here is an example that shows exactly why.
Inventory and payment race conditions
A customer adds a product to their cart and begins checkout.
Step one: Check inventory availability. The product is available. You do not reserve it yet — you only check availability.
Step two: Process payment.
Between step one and step two, five other customers complete their purchases. The inventory is now exhausted.
Step two succeeds. Payment captured.
Step three: Reserve inventory. Fails. No stock left.
Now you have a charged customer and no product to ship. You need to refund the payment. That is a compensating transaction.
The harder version
You decide to reserve inventory at step one to prevent this problem. But reservations time out after ten minutes.
An hour later, the customer returns and completes payment. Step two succeeds. Step three fails — the inventory is gone. Same result: charged customer, no product.
Why this matters
Sagas are not just about technical failures like network timeouts or crashed services. They are about business failures that happen in the gap between steps — inventory exhaustion, price changes, fraud flags, regulatory holds.
The system must detect these failures and trigger compensations. That is what sagas give you.
Other scenarios where sagas fit
Travel booking — flight, hotel, car, payment, confirmation. Each in a different service. If the car reservation fails after the flight and hotel are booked, you need to release the flight and hotel. Sagas give you that recovery path.
Loan approval — credit check, income verification, approval, disbursement, documents. The process takes minutes or hours. You cannot hold a database transaction open that long. A saga stretches the transaction across time with explicit compensations at each step.
Order fulfillment — inventory reservation, payment, shipping label, warehouse notification. If shipping fails after payment succeeds, you need to refund and release inventory.
Supply chain coordination — raw materials, production scheduling, logistics. External services with unpredictable response times. A material shortage discovered mid-saga means compensating previous steps.
Three conditions must be true before you consider a saga.
One — The transaction spans multiple independent services that do not share a database.
Two — Partial completion is problematic and must be undone through explicit business actions, not database rollbacks.
Three — Your business accepts that consistency will be eventual rather than immediate.
When those three conditions are present, a saga is worth considering.
Real Failure Modes in Production
This is the section that separates teams who have actually run sagas in production from teams who have only designed them. Each failure mode below is a real thing that happens to real systems.
Zombie Sagas
A saga starts. Several steps succeed. A failure occurs. Compensations begin. Then the orchestrator crashes before marking the saga as complete.
When it restarts, it does not know whether compensations finished. The saga is stuck in an intermediate state, neither fully compensated nor moving forward — a zombie.
Detection requires scheduled jobs that scan for sagas in intermediate states for longer than expected. Every saga must have a maximum expected duration, and any saga that exceeds it triggers an alert and a manual review process.
Split-Brain Sagas
Two orchestrator instances believe they are managing the same saga simultaneously. This happens when you run multiple orchestrator instances without proper distributed locking or leader election.
Prevention requires giving every saga a unique ID and making all operations idempotent so that even if two instances race, the second attempt produces no additional effect. Only one instance should ever actively manage a given saga at a time.
Out-of-Order Events
In choreographed sagas, events may arrive out of order. A CarBooked event might arrive before the FlightBooked event that should have preceded it.
Services must be designed to handle this. The common approach is to buffer events that reference saga state not yet seen, and to reprocess them once the expected prior state is confirmed.
Double Execution
The same step runs twice because the orchestrator sent BookFlight twice — once on the original attempt and once on a retry after a network timeout when the original request actually succeeded.
Prevention requires idempotency throughout. The flight service must check whether a booking already exists for this saga ID before creating a new one. This is true for every step, both forward and compensation.
Compensation Drift
Over time, forward logic evolves. New pricing rules are added. New validation steps are introduced. New side effects appear. But compensation logic gets forgotten. It is not updated in the same pull request. It drifts silently out of sync with the forward path.
A concrete example: you add loyalty points deduction to the booking flow. When a booking succeeds, loyalty points are deducted. But nobody updates the compensation logic to restore those points when a booking is cancelled. Now, every failed booking permanently costs the customer their points.
Prevention requires treating compensation as a first-class concern in every code review. When forward logic changes, explicitly ask: which compensation needs to change too? Write tests that verify the forward-and-compensation pair together. Consider versioning your sagas so that older in-flight sagas use the compensation logic that matches the forward logic they started with.
Pivot Transactions: The Irreversible Moments
Not all steps in a saga are equally reversible. Some steps — a payment capture, a regulatory filing, a physical dispatch — are very expensive or impossible to reverse once taken. These are called pivot transactions.
The rule is simple: place pivot transactions as late in the sequence as possible.
Everything before the pivot should be easy to release: reservations that can be cancelled, holds that can be lifted. Everything after the pivot should be designed knowing that going back is costly or impossible.
In travel booking, the pivot is payment capture. Before that point, flight reservations, hotel holds, and car reservations can all be released cleanly. After payment capture, sending a confirmation email cannot be unsent, and loyalty points deductions are difficult to reverse.
When you design a saga, identify your pivot transaction first. Then arrange every other step in relation to it. Steps that are easy to undo come before. Steps that are hard to undo come after. This single design decision will prevent more real-world problems than almost anything else in this article.
What Happens When Compensations Fail
Compensations are themselves operations — network calls to other services. They can fail for the same reasons any other operation fails: timeouts, unavailability, bugs.
Your saga must have a plan for this. "Run compensations and hope they succeed" is not a plan.
Retry with backoff is the first line of defence. If a compensation is idempotent — and it must be — you can retry it safely several times before giving up. Use exponential backoff with jitter to avoid thundering herd problems.
Dead letter queues with manual intervention handle the cases that automatic retry cannot fix. If refunding a payment fails for reasons that suggest a deeper problem — incorrect account details, a downstream bank outage — you need a human to investigate. The failed compensation message should land in a queue that triggers an alert and creates a support ticket.
Escalation to operations is the ultimate backstop. When a customer has been charged and the compensation to release their flight fails permanently, a human must fix it. Your system should make this visible immediately, not bury it in logs.
A saga without a defined plan for compensation failure is incomplete. Treat failed compensations with the same seriousness as failed forward steps.
Latency and the User Experience Trade-Off
Sagas move consistency from before the response to after the response. This has a direct and often underestimated effect on what users experience.
In a synchronous saga, the user waits while every step executes in sequence. They see the final result — success or compensated failure — when they get their response. Latency is roughly the sum of all step latencies, which accumulates quickly when network calls are involved.
In an asynchronous saga, you respond immediately and the saga runs in the background. From the user's perspective, the system feels instant. But the user may see intermediate states — "Your booking is being confirmed..." — before the final outcome is known. If the saga ultimately fails, they may already have received a preliminary confirmation that then has to be walked back.
Neither approach is wrong. They reflect different trade-offs between latency and certainty. The important principle is to make this choice deliberately and design your user experience around it explicitly. Show meaningful processing states. Provide polling endpoints or webhooks so users can check status. Do not pretend a saga completed instantly when it has not.
Implementation: Orchestration Approach
An orchestrated saga is built around a coordinator service that manages the entire flow. The coordinator persists its state to a database before each step — this is non-negotiable.
Here is the orchestrator logic in plain pseudocode for a travel booking saga:
The compensation logic mirrors the forward path in reverse:
The orchestrator must write state to the database before making each service call. If it crashes after successfully reserving the car but before updating state to CAR_RESERVED, it will not know to release the car when it restarts. Persisting state first closes this gap.
Implementation: Choreography Approach
In a choreographed saga, there is no coordinator. Each service publishes events that trigger the next service. Here is the event flow for the same travel booking saga:
Forward path:
Failure handling:
Notice the challenge: no single service holds the complete saga state. The flight service releases its seat without knowing exactly how far forward the saga progressed. This is why choreography works best for linear flows with straightforward compensations.
Correlation IDs are not optional here. Every event must carry the saga ID, and every service must log it on every line. Without this, tracing a failed saga across distributed logs becomes nearly impossible.
Implementation Checklist
These are the properties that separate a production-ready saga from a prototype that will fail unpredictably under load.
Idempotency. Every operation — both forward and compensation — must be safe to execute twice with the same result. Use the saga ID as the idempotency key. The flight service must check whether a reservation already exists for this saga ID before creating a new one.
Correlation IDs. Every saga gets a unique correlation ID at creation. Every event, every log line, every metric carries this ID. Without it, you cannot reconstruct what happened to any specific saga from your logs. This is the single most important observability requirement.
Timeouts. Every step has a maximum wait time. No saga waits forever for a service to respond. If the hotel service does not respond within the defined window, the saga treats it as a failure and begins compensation.
State persistence. In orchestrated sagas, the coordinator must write its current state to a persistent store before making each service call. This is the only way to survive crashes mid-saga.
Compensation tests. Write automated tests for every failure path. Test what happens when step two fails. Test what happens when step four fails. Test what happens when a compensation fails. Test what happens when the orchestrator crashes mid-saga. If you cannot simulate these failures in a staging environment, you are not ready to run sagas in production.
Observability dashboards. Track how many sagas are currently in flight, how many have failed, how many have become zombies, and what the average duration is per step. Sagas that do not appear in dashboards do not exist from an operational perspective.
Summary
In a monolith, consistency is guaranteed before the user gets a response. In a saga, consistency is achieved after the response — through successful completion or through compensation.
A saga is not about how systems succeed. It is about how systems recover when success is no longer possible.
The core reframe: A saga is a failure management system. It is defined as much by its rollback plan as by its forward plan.
Why two-phase commit fails: It sacrifices availability for consistency. When any participant is unavailable, the entire transaction blocks. In a microservices architecture, that is unacceptable.
When to use sagas: Travel booking, loan approval, order fulfillment, supply chain coordination — wherever you have multi-step processes across independent services, reversal is possible, and eventual consistency is acceptable.
When not to use sagas: Strong consistency required, compensation impossible, trivial flows, or team without distributed systems experience. The test is concrete: if you cannot simulate failure in staging, do not use sagas in production.
Orchestration vs choreography: Orchestration centralises control for visibility and debuggability. Choreography decentralises for autonomy and scale. As conditional logic grows, sagas tend toward orchestration. Keep the coordinator lean.
The hardest part is state. Orchestration gives you centralised, explicit state. Choreography gives you distributed, implicit state. Choose based on your operational capacity to debug each model.
The most common production killer is compensation drift — forward logic that evolves while compensation logic stays frozen. Treat compensation as first-class in every code review.
Most teams design the happy path carefully, test it thoroughly, and deploy it confidently. Then production arrives — with its partial failures, its crashed coordinators, its out-of-order events — and the recovery path turns out to be buggy, the compensations are stale, and the system drifts quietly into inconsistency.
Do not make this mistake. Design the failure path first. Ask "what happens when this step fails?" before you write the step itself. The saga pattern is only as strong as the answer to that question.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.