Learning Paths
Last Updated: March 16, 2026 at 17:30
Client–Server Architecture Explained: Request–Response Communication and Modern Web System Design
Understanding the client–server interaction model, request–response communication, typical web architectures, and how load balancers enable scalable distributed systems
Modern software systems rarely run as a single program on a single computer. Instead, most applications rely on a separation between clients that request services and servers that provide them. This tutorial introduces client–server architecture, explaining how request–response communication works and how modern web systems are structured. Through real-world examples such as web applications, mobile apps, and APIs, you will learn how load balancers enable systems to scale to millions of users. By the end of this tutorial, you will understand why the client–server model remains one of the most fundamental architectural patterns in distributed computing
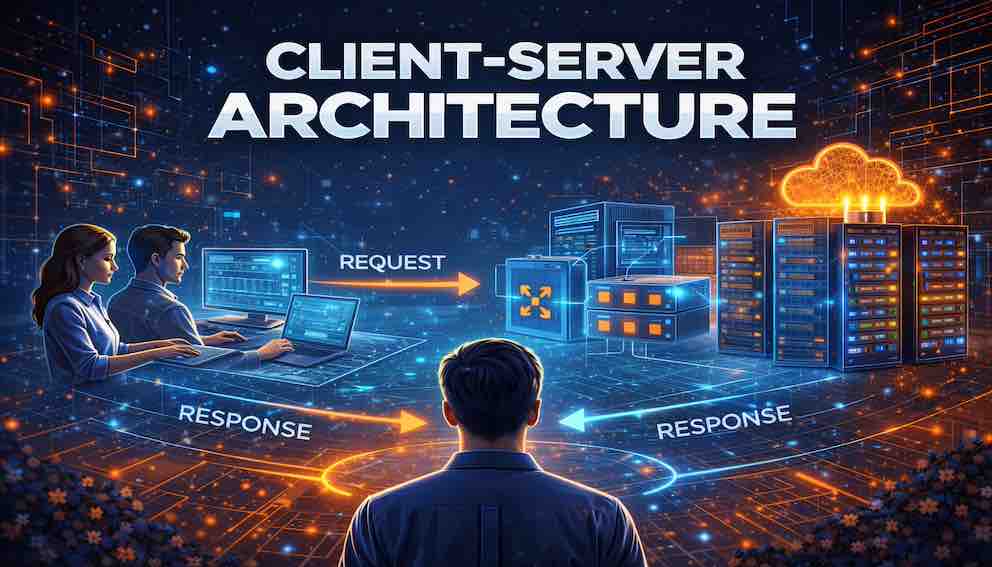
Introduction: Why Distributed Systems Need Structure
Imagine computing in its earliest days.
You sat at a single machine — a personal computer, perhaps, or a terminal connected to a mainframe. The program you ran lived entirely on that machine. Your word processor stored documents locally. Your spreadsheet calculated numbers using only the processor in front of you. There was no concept of "the cloud," no "syncing," no "server unavailable" messages.
If you wanted to share a file, you handed someone a floppy disk.
That world feels distant now. Today, when you open a website, your browser communicates with servers potentially thousands of miles away. When you check the weather on your phone, an app sends requests to services you'll never see. When you read email, your device talks to mail servers that hold your messages until you're ready.
Computing has become distributed. And with distribution comes a fundamental question: if different machines handle different parts of an application, how do they know what to do?
Without some organising principle, distributed systems descend into chaos. Machines duplicate work. They compete for resources. They communicate inefficiently, or not at all.
This is why one of the oldest and most enduring patterns in software architecture emerged: the client–server model.
It's a simple idea with profound implications. Some components in a system request services. Other components provide them. That separation — between those who ask and those who answer — structures everything from the smallest web application to the largest cloud platform.
You encounter this pattern constantly, whether you realise it or not. Every time you browse the web, your browser acts as a client. Every time you use a mobile app, that app is a client. Every time you call an API from code, your program becomes a client.
And behind each of those requests, somewhere, a server is listening.
In this tutorial, we'll explore what client–server architecture really means. We'll walk through how request–response communication works, examine how modern web systems layer responsibilities, and see how load balancers help systems scale to millions of users. By the end, you'll recognise this pattern everywhere — and understand why it's so fundamental to how we build software today.
A Scene You Might Recognise
Picture yourself at a restaurant.
You sit at a table, browsing the menu. When you're ready, you signal a waiter. The waiter comes to your table, takes your order, and disappears into the kitchen. Some time later, they return with your food.
This everyday interaction is a perfect metaphor for client–server architecture.
You, the diner, are the client. You initiate the interaction. You request a service — in this case, a meal.
The waiter and kitchen together form the server. They receive your request, process it (the kitchen cooks), and return a response (the waiter brings your food).
Notice what's not happening. You don't go into the kitchen to cook for yourself. The kitchen doesn't come to your table to ask what you want without being summoned. There's a clear separation of responsibilities and a clear pattern of communication: request, then response.
This separation is what makes restaurants work. The kitchen can focus on cooking. The waitstaff can focus on serving. You, the diner, can focus on enjoying your meal. Each part of the system does what it does best, and they coordinate through a well-understood interaction pattern.
Client–server architecture in software works exactly the same way.
The Client–Server Interaction Model
At its core, client–server architecture is built on a simple idea: some components request services, and other components provide them. These two roles — requester and provider — define the entire model.
The Role of the Client
A client is any component that initiates communication with another component to request a service.
In most modern systems, clients are what users actually touch. They're the interfaces between people and the complex machinery behind the scenes. A client typically:
- collects input from you — clicks, taps, typed text
- sends requests to servers, asking for data or actions
- receives responses and interprets them
- presents results in a way you can understand and act upon
You interact with clients constantly without thinking about it. Your web browser is a client. Your mobile banking app is a client. The email program on your desktop is a client. The Slack application you use to communicate with colleagues is a client.
Each of these programs shares a common trait: they don't do the heavy lifting themselves. They ask other systems to do that work, then show you the results.
Consider a simple example. You open your weather app to check today's forecast. The app doesn't have a built-in weather sensor. It doesn't run atmospheric models. It does one thing: it sends a request to a weather service asking, "What's the forecast for my location?" The app is a client. Its job is to ask, then show you the answer.
The Role of the Server
A server is a component that receives requests from clients and performs services in response. Servers do the work that clients can't or shouldn't do themselves:
- they process business logic — calculating prices, validating orders, enforcing rules
- they access databases, retrieving and storing information
- they coordinate with other servers when necessary
- they generate responses that clients can display
Returning to the weather example, somewhere out there is a server that received your app's request. That server might look up your location, query a database of weather models, run calculations to generate a forecast, format that forecast into a response, and send it back to your app — all without ever knowing anything about your phone or your preferences. It simply responds to requests.
The Power of Separation
This separation — between clients that ask and servers that answer — is what makes client–server architecture so powerful.
Because clients and servers are separate, they can evolve independently. A company can redesign its mobile app completely without changing the server logic. Users get a fresh new interface, but the backend services keep working exactly as they always have. Similarly, server teams can optimise databases, improve algorithms, or migrate to new infrastructure without affecting client applications. As long as they maintain the same request–response contract, clients never know anything changed.
This independence allows different teams to work in parallel. It allows systems to grow organically. It allows companies to upgrade parts of their technology stack without rebuilding everything at once.
Reflective question: Think about an application you use that has both a web version and a mobile app. Have you ever noticed that they feel different but work the same? That's the client–server separation in action.
Request–Response Communication
If clients request and servers respond, how does that conversation actually happen?
The answer is a communication pattern so ubiquitous that we rarely think about it: the request–response model. Let's walk through it step by step.
Step 1: The Client Sends a Request
The cycle begins when a client needs something from a server. The client prepares a message — a request — and sends it across the network. That request typically contains:
- what operation the client wants performed (e.g., "get product details," "place order," "authenticate user")
- parameters or data associated with the request (e.g., product ID, order items, username and password)
- metadata such as authentication tokens, client identification, or caching instructions
In web applications, this request often takes the form of an HTTP message. HTTP defines a small set of standard methods — GET for retrieving data, POST for submitting data, PUT and PATCH for updating resources, and DELETE for removing them. But the request–response pattern exists across many protocols: database queries, email retrieval, and file transfers all follow similar structures.
Step 2: The Server Receives the Request
The server isn't just sitting idle. It's listening — continuously waiting for requests to arrive.
When a request reaches the server, it examines the message to understand what's being asked. This typically involves validating that the client is authorised to make the request, checking that required parameters are present, and determining which part of the system should handle it. For popular services, servers do this thousands or even millions of times per minute, in milliseconds.
Step 3: The Server Processes the Request
Now the real work begins. The server executes whatever logic is needed to fulfil the request. This might mean running business logic, retrieving data from a database, performing calculations, or coordinating with other services. When a server calls out to another service to complete a request, it temporarily becomes a client itself — a common pattern in modern distributed systems.
This processing step is where the most complex code lives. It's the heart of the application, where raw requests become meaningful results.
Step 4: The Server Sends a Response
Once processing is complete, the server prepares a response. This typically contains the requested data or result, a status indicator telling the client whether the request succeeded or failed, and optional metadata such as caching directives.
In HTTP-based systems, status codes carry important meaning. Codes in the 200 range signal success. The 400 range signals client errors — for example, a 404 indicates the requested resource was not found, and a 401 indicates the client is not authenticated. Codes in the 500 range signal server-side errors. Understanding these codes is essential for anyone building or debugging client–server systems.
The server sends the response back across the network to the client that made the request.
Step 5: The Client Receives and Displays the Response
Finally, the client receives the response and presents it to the user. A web browser renders HTML into a formatted page. A mobile app updates its display with new data. A command-line tool prints results to the terminal.
The user sees the result of their action — the product page loads, the order confirms, the weather appears — and the cycle is complete. All of this, from click to display, happens in moments. But behind that seamless experience is a carefully choreographed conversation between systems that may be continents apart.
A Concrete Example
Let's make this concrete with a familiar scenario: visiting an online store.
You type www.examplestore.com/products into your browser and press Enter.
Your browser (the client) sends an HTTP GET request to the server, asking for the /products resource. The server receives this request, checks that you're allowed to see the products, and determines that the request should be handled by the product catalogue service. That service queries a database, applies any filters or sorting, and formats the results into an HTML page. The server sends that page back to your browser in an HTTP response. Your browser receives the HTML, renders it, and displays it on your screen.
From your perspective, you typed a URL and a page appeared. From the system's perspective, a complete request–response cycle just executed, coordinating browser, server, database, and network to deliver that experience.
Typical Web Architecture: Layers of Responsibility
In the early days of the web, a single server might handle everything. The same machine that received HTTP requests also ran application code and stored data in a local file system. That approach worked for small sites with limited traffic. But as the web grew, architects discovered that separating responsibilities into distinct layers made systems more manageable, scalable, and resilient.
Modern web systems typically organise themselves into several layers, each with a clear responsibility.
The Client Layer
At the edge of the system, closest to users, sits the client layer. This is where user interaction happens: web browsers rendering HTML pages, mobile applications running on phones and tablets, desktop clients installed on computers, and smart devices and IoT interfaces.
The client layer's job is to present information and capture user intent. It doesn't store authoritative data or execute core business logic. It delegates that work to the layers behind it.
The Web Server Layer
When a request arrives from a client, the first server component it encounters is typically a web server. Web servers like Nginx or Apache handle the initial connection. Their responsibilities include managing HTTP connections efficiently, serving static files (images, CSS, JavaScript) directly without involving application code, routing dynamic requests to appropriate application services, and enforcing basic security policies like rate limiting or IP filtering. These servers are optimised for high concurrency — handling thousands of simultaneous connections without breaking a sweat.
The Application Server Layer
Behind the web server sits the application server layer. This is where the unique logic of your application lives.
Application servers run code written in frameworks like Node.js for JavaScript, Spring Boot for Java, Django or Flask for Python, and Ruby on Rails or Laravel for their respective languages. These servers execute the business logic that makes your system distinct: processing orders, managing authentication, generating personalised recommendations, and enforcing validation rules.
Unlike web servers, which are relatively generic, application servers are where your team's specific expertise and domain knowledge lives.
The Database Layer
Behind application servers sits the foundation: the database layer. Databases store the persistent information that outlasts any single request or session — product catalogues, user profiles, order histories, and content metadata.
When an application server needs data, it queries the database. When it needs to record something permanently, it writes to the database. The database ensures that data remains consistent, durable, and available even if application servers restart or fail.
It's worth distinguishing between two broad categories. Relational databases (such as PostgreSQL or MySQL) organise data into structured tables and are well-suited for data with clear relationships and strong consistency requirements. Non-relational databases (such as MongoDB or Redis) offer more flexible data models and are often chosen for use cases that prioritise performance, scalability, or schema flexibility. Many production systems use both, choosing the right tool for each type of data.
How the Layers Work Together
A request flows through these layers in sequence:
Client → Web Server → Application Server → Database → Application Server → Web Server → Client
Each layer does its part, then passes responsibility along. The web server handles the connection, the application server executes logic, the database stores and retrieves data, and the results flow back out.
This separation means each layer can be optimised independently. You can scale web servers differently from application servers. You can upgrade the database without touching application code. You can replace the client entirely — moving from web to mobile — while leaving the backend layers unchanged.
Reflective question: Think about a web application you use regularly. Can you imagine where the boundaries between these layers might be? What does the client handle? What must the server do?
Scaling Client–Server Systems
A beautiful thing happens when you build a system with clear layers and separation of concerns: it becomes possible to scale. Scaling means handling more users, more requests, more data — without falling over. In client–server systems, there are two fundamentally different ways to do this.
Vertical Scaling: Building a Bigger Machine
Vertical scaling means making a single server more powerful — adding CPU cores, more memory, faster disks, better network cards. It's straightforward: you don't change your architecture; you just buy better hardware. For a time, this works.
But eventually, you hit limits. There's only so much memory a single machine can address, and only so fast a single CPU can go. At some point, the cost of increasingly powerful hardware becomes prohibitive. Vertical scaling also creates a single point of failure: if that one powerful machine goes down, everything stops.
Horizontal Scaling: Adding More Machines
Horizontal scaling takes a different approach. Instead of building a bigger machine, you add more machines. You start with one server. When traffic grows, you add a second, then a third, then a hundred.
Horizontal scaling offers compelling advantages. Growth is virtually unlimited — need to handle more traffic, add more servers. Resilience improves — if one server fails, others keep working. Cost is often lower — many modest servers frequently cost less than one super-powered machine.
But horizontal scaling introduces a new challenge: how do you distribute requests across all those servers? You can't have clients guessing which server to contact. You need something in between — something that receives all requests and decides where each one should go.
That something is a load balancer.
Scaling with Load Balancers
A load balancer is a component that sits between clients and servers, distributing incoming requests across multiple backend servers. Instead of clients communicating directly with individual servers, they communicate with the load balancer, which forwards each request to one of the available servers.
The flow looks like this:
Client → Load Balancer → Server 1 (or Server 2, or Server 3, or Server N)
What Load Balancers Do
Distribution. Load balancers spread requests across servers so no single server becomes overwhelmed. Different algorithms govern how this works. Round-robin distributes requests evenly in rotation. Least connections routes new requests to the server handling the fewest active connections. IP hash consistently routes a given client to the same server based on their IP address. Each algorithm suits different workloads.
Health checking. Load balancers regularly check whether backend servers are healthy. If a server stops responding or returns errors, the load balancer stops sending it traffic until it recovers.
Session persistence (optional). Some applications need a user's requests to go to the same server each time — for example, when session state is stored locally on a server rather than in a shared database. Load balancers can remember which server handled a user's first request and route subsequent requests accordingly. This is sometimes called "sticky sessions."
SSL termination. Load balancers can handle the encryption and decryption of HTTPS traffic, offloading that CPU-intensive work from application servers and simplifying certificate management.
A Concrete Scaling Example
Imagine an online store preparing for a major sale. Thousands of customers will visit simultaneously. Without load balancers, the architecture is straightforward but fragile:
Browser → Single Web Server → Single App Server → Database
That single web server will quickly become overwhelmed. Requests will time out. Users will see errors.
With load balancers and horizontal scaling, the architecture transforms:
Browser → Load Balancer → Web Servers (1, 2, 3) → Load Balancer → App Servers (1, 2, 3) → Database Cluster
Now, when thousands of requests arrive, the first load balancer spreads them across multiple web servers. Those web servers pass requests to a second load balancer, which distributes them across multiple application servers. If any server fails, the load balancers automatically stop sending traffic to it. The system scales, survives failures, and handles traffic that would have crushed a single server.
A Complete Example: Food Delivery Platform
Let's bring everything together with an end-to-end example: a food delivery platform.
A customer opens the mobile app, browses restaurants, and places an order. Here's what happens behind the scenes.
The mobile app — the client — displays restaurant menus, captures the order, and shows status updates. When the customer taps "Place Order," the app constructs a request containing the order details (restaurant, items, delivery address, payment method) and sends it to the platform's API.
That request first hits a load balancer, which examines it and forwards it to one of many available API servers. An API server receives the request, validates the order, checks restaurant availability, processes payment by calling a payment service (acting as a client itself), and records the order in the database. The database confirms the write, and the application server prepares a response. The response travels back through the load balancer to the mobile app, confirming that the order was received. The customer sees "Order Confirmed" on their screen.
Now imagine this platform grows to serve millions of users. The architecture scales horizontally: more API servers are added behind the load balancer, the database is replicated to handle more reads, caching layers reduce load on the database, and additional load balancers manage different types of traffic.
The core client–server pattern remains unchanged. Clients still request; servers still respond. But the system now handles orders at a scale that would have been impossible with a single server.
Connecting to Earlier Architecture Concepts
Client–server architecture doesn't exist in isolation. It connects directly to broader architectural concepts.
Architecture Views and Perspectives
Client–server systems can be understood through all four classical architectural views:
The logical view shows the system as clients, servers, and the services they exchange. The development view reveals that client code and server code are separate codebases, often maintained by different teams. The process view describes how request–response interactions flow between processes across network boundaries. The deployment view shows clients running on user devices, servers running in data centres or cloud regions, and load balancers sitting between them.
Each view reveals something different about how the system works.
Architecture Drivers
Why choose client–server architecture? Because it serves certain drivers particularly well: scalability (servers can be scaled horizontally behind load balancers), centralised control (business logic and data live on servers, making updates easier), support for multiple client types (the same server can support web, mobile, and desktop clients), and security (sensitive data never leaves servers; only necessary information travels to clients).
Common Pitfalls in Client–Server Systems
Even well-designed architectural patterns can be implemented poorly. Here are pitfalls to watch for.
Tight coupling between clients and servers. If clients depend on specific server implementations — expecting particular data formats or relying on internal server details — then changing servers becomes difficult. The remedy is to design clean, stable APIs that hide server implementation details and let clients depend on contracts, not internals.
Overloaded servers. If a system grows but the server side doesn't scale, servers become overwhelmed and response times increase. The remedy is to monitor server load, scale horizontally before servers reach capacity, and use load balancers to distribute traffic.
Poorly designed APIs. If APIs are inconsistent, poorly documented, or change without warning, client development becomes painful. Invest in API design, treat APIs as products, document them thoroughly, and version them carefully.
Ignoring caching. If every request travels all the way to the database, servers work harder than necessary and response times suffer. Cache appropriate data at multiple levels — in the client, at the load balancer, in application memory, and in dedicated caches like Redis or Memcached.
The chatty client problem. If clients make dozens of small requests where one larger request would suffice, network overhead multiplies. Design APIs that let clients batch requests or request exactly what they need. GraphQL, for example, lets clients specify exactly the data they want in a single request, eliminating the over-fetching and under-fetching common in traditional REST APIs.
Ignoring network failures. Networks are unreliable. Requests can be lost, responses can arrive late, and servers can become temporarily unavailable. Robust client–server systems handle these realities through timeouts, retries with exponential backoff, and graceful degradation — showing cached data or a helpful error message rather than simply crashing.
When to Choose Client–Server Architecture
Client–server architecture shines in these common scenarios:
Shared Data Needs. Multiple users or applications need consistent access to the same information—like a product catalog, customer database, or document repository.
Centralized Control. You need to enforce business rules, security policies, or compliance requirements from a single authoritative source rather than trusting every client to behave correctly.
Multi-Platform Support. The same backend must serve different client types—web browsers, mobile apps, desktop applications, or third-party integrations.
Scalable Growth. You anticipate increasing traffic over time and want the flexibility to add server capacity without redesigning the entire system.
Independent Evolution. Different teams need to update clients and servers on their own schedules, as long as they honor the same API contract.
This combination of characteristics explains why client–server has become the default choice for web applications, mobile backends, cloud services, and enterprise systems. It's not always the most exciting architecture, but it reliably solves a vast range of practical problems.
When to Look Beyond Client–Server
The client–server model has limits. Consider other patterns when:
Peers Are Equals. In peer-to-peer systems like file-sharing networks or blockchain nodes, every participant acts as both client and server. The asymmetry of client–server doesn't fit.
Connectivity Is Intermittent. Offline-first applications—think note-taking apps that sync when online—can't depend on a server being reachable. They need local autonomy with background synchronization.
Latency Cannot Be Tolerated. Real-time collaboration tools (Figma, Google Docs) or financial trading systems need updates faster than a round-trip to a server allows. Direct peer communication or local processing becomes essential.
Every Millisecond Matters. Some gaming, IoT, or industrial control systems have timing constraints that make even a single network hop too expensive.
For these scenarios, architects often turn to peer-to-peer networks, event-driven architectures, edge computing, or local-first designs. Each trades the simplicity of client–server for capabilities the classic model can't provide.
The Bottom Line: Client–server isn't universal, but its sweet spot covers most business applications you'll encounter. Start there, and migrate to more complex patterns only when your requirements demand it.
Conclusion: The Pattern That Built the Modern Web
Client–server architecture is one of the most fundamental patterns in all of software engineering.
It emerged from a simple observation: when systems become distributed, someone needs to request and someone needs to respond. That separation — between clients that ask and servers that answer — has structured everything that followed.
The web runs on this pattern. Every website you visit, every API you call, every mobile app you use follows the same basic choreography. A client requests; a server responds.
But as we've seen, that simple pattern scales into sophisticated systems. Load balancers distribute traffic across server farms. Layered architectures separate concerns into web servers, application servers, and databases. Caching reduces latency. Horizontal scaling handles millions of users.
Understanding client–server architecture gives you a lens for seeing how modern systems work. When you open an app and data appears, you'll recognise the request–response cycle that made it possible. When a service scales to handle massive traffic, you'll understand the load balancers and horizontal scaling behind it.
This pattern won't solve every architectural problem. But it solves so many, so elegantly, that it has become the default choice for a vast range of systems.
As you continue your journey through software architecture, you'll encounter patterns that build on this foundation — microservices, event-driven architectures, service meshes. Each extends the basic client–server idea in new directions. But the core remains: some components request, others respond. And that simple separation structures the distributed systems that power our digital world.
Key Takeaways
Client–server architecture separates systems into requesters (clients) and providers (servers), allowing independent evolution and clear responsibility boundaries.
The request–response model defines how clients and servers communicate: the client sends a request, the server processes it, the server returns a response, and the client displays the result.
Modern web systems layer responsibilities: clients handle presentation, web servers manage connections, application servers execute logic, and databases store data.
Load balancers enable horizontal scaling by distributing requests across multiple servers, improving both capacity and resilience. Common algorithms include round-robin, least connections, and IP hash.
HTTP status codes are a fundamental part of request–response communication: 2xx signals success, 4xx signals client errors, and 5xx signals server errors.
Databases come in relational and non-relational forms, and many production systems use both, choosing the right tool for each type of data.
Common pitfalls include tight coupling, overloaded servers, poorly designed APIs, ignoring caching, chatty clients, and failing to handle network failures gracefully.
Client–server fits naturally when you need shared data, centralised control, multiple client types, or scalable services.
The pattern is everywhere — once you recognise it, you'll see it constantly.
Your Next Steps
Before moving to the next tutorial, take a moment to observe the client–server systems around you.
Open a website and notice: your browser is a client. Where might the servers be? What layers might exist between you and the database? Use your browser's developer tools (F12 in most browsers) to inspect the Network tab — you'll see the actual HTTP requests and responses happening in real time.
Use a mobile app and consider: what requests is it making? What responses is it receiving? How would the system behave if you turned off your network connection?
Think about systems you've built or worked on: were they client–server? Where were the boundaries? How did they scale? What pitfalls did you encounter?
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.