Learning Paths
Last Updated: May 9, 2026 at 16:30
Platform Engineering in Microservices: Why Platform Teams Exist and When to Build One
The hidden cost of microservices independence — and the engineering discipline built to solve it
Microservices promise team autonomy, but as systems grow, every team quietly starts rebuilding the same infrastructure: logging, deployment pipelines, retries, observability, and security controls. This article explains why platform engineering emerged as the discipline designed to solve that duplication problem, and how platform teams create shared foundations without destroying service independence. It explores Internal Developer Platforms (IDPs), Team Topologies, DORA metrics, and the dangerous anti-pattern of turning shared libraries and parent POMs into a distributed monolith. Most importantly, it explains the central balancing act of modern platform engineering: standardise interfaces and operational foundations while preserving the freedom for teams to evolve their services independently.
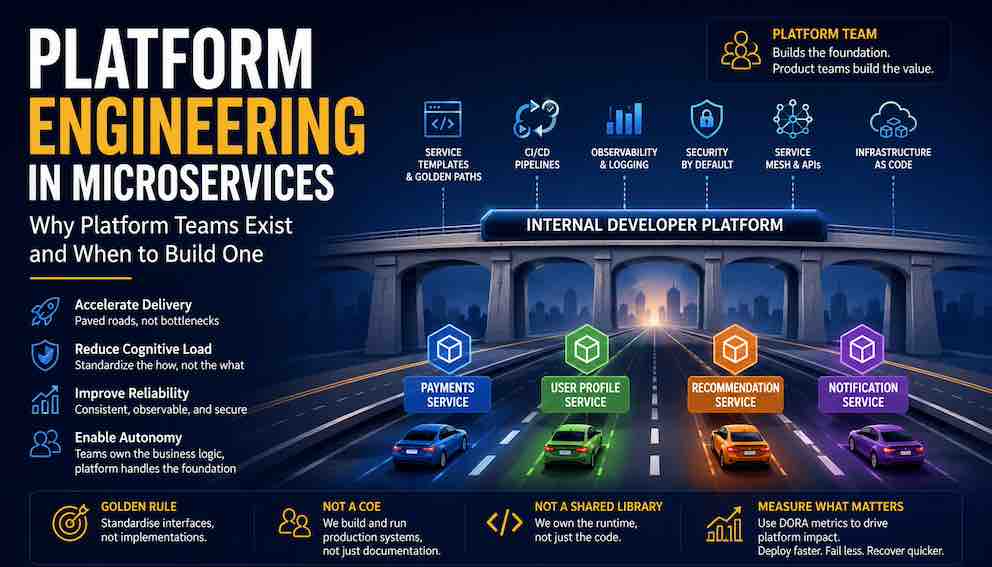
Every team ships faster when they stop rebuilding the same underlying infrastructure from scratch. That underlying infrastructure — the authentication, logging, retry logic, observability pipelines, deployment tooling, and service discovery mechanisms that every service needs just to exist — is what engineers mean when they talk about "plumbing." Platform teams exist to build and maintain that plumbing once, so everyone else can focus on their actual product. This article explains what a platform team is, what it owns, how it differs from a Centre of Excellence or a shared library, when to build one, and what separates a platform team that accelerates development from one that quietly becomes the biggest bottleneck in the building.
The Problem That Creates the Need
Most engineering organisations do not adopt microservices because they love distributed systems. They adopt them because a large, tangled codebase has made it impossible for teams to ship independently without stepping on each other. Splitting the monolith feels like the answer. Give each team ownership of a service, let them deploy on their own schedule, and watch the bottlenecks disappear.
For a while, that is exactly what happens. Teams move fast. Deployments become smaller and safer.
Then, slowly, the pain shifts rather than disappears.
Every team, no matter how focused their business logic, eventually has to solve the same set of infrastructure problems. A service needs authentication. It needs structured logging so that errors are searchable. It needs retry logic and timeouts for when it calls other services, because networks are unreliable. It needs observability — metrics, traces, dashboards — so engineers can understand what the service is doing in production. It needs a deployment pipeline, IAM roles, health checks, and a way to register itself so other services can find it.
None of this is the business logic that makes the company valuable. It is the plumbing that keeps the lights on.
What tends to happen next is that each team builds this plumbing on their own. Team A writes a retry utility one way. Team B, unaware or pressed for time, writes something slightly different. Team C copies an old snippet from an internal wiki. Six months later, these implementations have silently diverged. One service emits rich, structured trace IDs. Another logs "something went wrong" with no context. One handles duplicate requests gracefully. Another creates double charges on a flaky network day.
The operational cost rises even though the business logic stays cleanly separated. There are now five approaches to authentication, three log formats, and no reliable way to trace a transaction that crosses four services. Teams were given independence, but what they got in practice was the burden of reinventing infrastructure independently. This is the duplication problem that platform teams are designed to solve.
What a Platform Team Actually Is
A platform team is an internal engineering team responsible for the shared infrastructure and developer tooling that every other engineering team depends on. They build, operate, and continuously improve the foundation that services run on — without owning any service's business logic.
The clearest way to understand this is through a principle that sounds paradoxical at first: independence in business logic depends on shared foundations.
If every team has to invent its own approach to logging, deployment, and security, those teams are not independent. They are burdened. Real autonomy comes from not having to think about the plumbing at all. A platform team standardises the how so that product teams can focus entirely on the what.
A useful analogy here is road infrastructure. A platform team builds and maintains the roads. Product teams drive their own vehicles, in their own direction, at their own pace. No one on the road crew tells drivers where to go. But everyone benefits from smooth tarmac, clear lane markings, and working traffic signals. Without those, each driver would have to navigate unpaved ground and lay their own gravel. That is the situation without a platform team.
When a platform team works well, the advantages ripple across the entire engineering organisation.
Better infrastructure utilisation. A single team managing the shared foundation can optimise for cost and performance in ways that dozens of individual teams never could. They see the full picture — which resources are under-used, which are over-provisioned — and can tune accordingly. Without a platform team, every team provisions their own siloed infrastructure, and waste accumulates invisibly.
Shared operational understanding. When every service uses the same logging format, the same metrics schema, the same deployment patterns, engineers can move between teams without relearning the entire infrastructure stack. On-call rotations become less terrifying because the observability tooling is universal. Incident post-mortems become more effective because the underlying systems are familiar to everyone.
Specialisation and deeper expertise. A product team asked to become experts in Kubernetes, IAM policies, and distributed tracing on top of their domain logic will be mediocre at all of them. A platform team can afford to go deep. They understand the sharp edges of the infrastructure because they live in it every day. That depth of expertise directly translates into fewer production incidents and more reliable systems.
Security and compliance as default. In a decentralised model, security becomes a patchwork. One team remembers to rotate secrets. Another hardcodes them in a config file. A platform team can embed security into the golden path. Secret management is handled automatically. Vulnerability scanning runs on every build. IAM roles follow a standard, audited pattern. Compliance requirements are met by default, not by manual effort from each team.
Product teams focus on what matters. This is the ultimate benefit. Every hour a product engineer spends debugging a flaky deployment pipeline or figuring out why their traces are missing is an hour they are not spending on the features that actually differentiate the business. A platform team absorbs that toil so that product teams can stay in their zone of highest contribution.
Faster and safer onboarding. A new engineer joining an organisation without a platform team faces a wall of unknown context. Which pipeline do I use? How do I get a service running locally? Where are the logs? Every team has different answers. With a platform team, a new engineer can generate a service from a template, run it locally with one command, and deploy it to a test environment within their first day. They learn one way — the platform way — and it works everywhere.
Sustained velocity over time. Here is a question worth sitting with: how does your organisation handle it when a better approach to logging emerges? Or when a security vulnerability requires every service to update a library? Or when the tracing standard changes?
Without a platform team, every team handles these moments separately. Some teams update quickly. Some delay. Some miss the change entirely. Over time, the system fragments. The fragmentation is not anyone's fault — it is just what happens when fifteen teams each have fifteen competing priorities. The organisation does not necessarily get slower. But it gets hairier. Debugging takes longer because services have drifted. Onboarding takes longer because every team does things slightly differently.
With a platform team, these moments become non-events. The platform team updates the golden path. Teams that follow the golden path get the improvement automatically. Teams that have deliberately chosen a different path can stay where they are. The system does not fragment because there is a single, maintained source of truth.
The advantage is not that a platform team makes you fast on day one. The advantage is that a platform team makes it easy to stay consistent across years and dozens of teams, without every team having to coordinate constantly. That is what "sustained velocity" actually means — not speed, but the removal of slow, cumulative friction.
This is why platform engineering has emerged as a recognised discipline in modern software organisations. It acknowledges that decentralisation without a shared foundation is not freedom — it is organised chaos. And it provides a clear, practical answer to that chaos.
Team Topologies: The Framework That Formalised This
The language around platform teams became significantly clearer with the publication of Team Topologies by Matthew Skelton and Manuel Pais. That framework distinguishes four fundamental team types:
- stream-aligned teams (product teams focused on a specific user journey or business domain)
- enabling teams (temporary experts who coach other teams through a capability gap)
- complicated subsystem teams (specialists for particularly complex technical components)
- platform teams.
In the Team Topologies model, a platform team's purpose is to reduce the cognitive load on stream-aligned teams. Every decision a developer has to make before writing a line of business logic — which logging library, which deployment approach, how to configure a health check — is cognitive overhead. The platform team makes those decisions once, makes them well, and then hides them behind simple, self-service interfaces.
This framing matters for a junior developer trying to understand the role. The platform team does not exist to enforce rules or to gatekeep infrastructure access. It exists to reduce the mental weight of working in a distributed system, so that the people building product features can spend their energy on the problems that actually matter to users.
What a Platform Team Owns — and What It Should Never Own
The scope of a platform team needs careful definition. A team that tries to own everything becomes a new monolith by a different name. A team that owns too little leaves the duplication problem unsolved.
A platform team typically owns the following areas:
Service templates and golden paths. A golden path is the recommended, well-supported way to create and operate a service. It is usually a project template or starter kit that arrives pre-configured with working authentication, structured logging, health check endpoints, and a deployment pipeline. A new engineer can generate a service from the template and have something running in production within hours, not days. The golden path is paved and smooth. Teams are not forced onto it, but it is clearly the easiest route.
CI/CD pipelines and deployment infrastructure. The platform team owns the mechanics of building, testing, and deploying services safely. This includes the pipeline definitions, the artifact registries, the rollout strategies, and the rollback mechanisms. Product teams configure what to deploy; the platform team owns how the deployment happens.
Observability standards and infrastructure. Consistent logging formats, a shared metrics system, distributed tracing, and the dashboards and alerting that sit on top of them. When a transaction crosses six services and something goes wrong, observability infrastructure is what makes it possible to find the problem in minutes rather than hours.
Service-to-service communication tooling. This might be a service mesh like Istio or Linkerd, a standardised RPC framework, an internal API gateway, or shared client libraries that handle retries, circuit breaking, and timeouts in a consistent way across all services.
Infrastructure modules for cloud and Kubernetes. Reusable Terraform or Pulumi modules for provisioning databases, queues, storage, and compute. IAM role templates. Kubernetes namespace configurations. These give product teams a safe, audited path to infrastructure without each team needing deep cloud expertise.
Security as a first-class concern. Shifting security left — embedding it into the development workflow rather than bolting it on at the end — is one of the most valuable things a platform team can do. This means vulnerability scanning in CI pipelines, secret management tooling, certificate rotation handled at the platform layer, and policy-as-code that catches misconfigurations before they reach production.
What a platform team does not own is equally important. It does not own domain logic. It does not dictate how the payments team models a refund, what fields the user profile service exposes, or how the recommendation engine ranks results. It does not make product decisions. The platform team owns the stage. The product teams own the play.
Platform Team vs Centre of Excellence: Not the Same Thing
Many organisations conflate a platform team with a Centre of Excellence, or CoE. They solve different problems and operate in fundamentally different ways.
A Centre of Excellence is advisory. It produces best-practice documentation, runs internal workshops, defines architectural standards, and creates governance checklists. Its influence on behaviour is through guidance. A CoE will tell teams that structured logging is important and document the recommended approach. But it does not build or operate the logging infrastructure.
A platform team builds and runs production-critical systems. When the log aggregation pipeline breaks at 2am, the platform team is paged. The CoE is not. A platform team directly changes systems. A CoE influences behaviour. One gives working software. The other gives advice. Both have value, but they are not interchangeable, and mistaking one for the other leads to an organisation that has excellent documentation and persistent infrastructure chaos.
Shared Libraries vs Platform Teams: Why Code Reuse Is Not Enough
A common early response to the duplication problem is creating a shared library — a central repository of common code that every service imports. This is a natural and sensible step. But shared libraries are not a substitute for a platform team, and understanding why is important.
A shared library solves code duplication. It does not solve operational duplication.
A library can provide a standardised HTTP client, but it cannot ensure every service has the correct dashboards and alert thresholds. It can provide a logging function, but it cannot run the log aggregation infrastructure. It can define a retry policy, but it cannot monitor whether that policy is behaving correctly across all services in production. It also introduces versioning problems: when the library needs to be updated, every team that depends on it must update their dependency, which often means the library version fragments across the organisation over time.
A platform team owns the runtime environment. They run the observability stack. They provision infrastructure. They operate the systems, not just provide the code. A shared library might be one output of a platform team, but it is not a replacement for the team itself.
The error pattern to watch for is an organisation concluding it does not need a platform team because it has a common library. What it actually has is code reuse without operational governance. The duplication moves from the code into the runtime environment, and it becomes harder to see — until an incident exposes how inconsistently the services are actually operating.
The Internal Developer Platform (IDP)
The term Internal Developer Platform, or IDP, appears frequently in conversations about platform teams. It is worth being precise about what it means.
An Internal Developer Platform is the collection of tooling, APIs, and interfaces that a platform team builds and exposes to developers. It is the product. The platform team builds the IDP. The IDP is what developers actually interact with day to day.
A well-designed IDP typically includes a self-service portal or CLI where a developer can provision a new service, request a database, configure a deployment pipeline, or inspect the health of their running service — without filing a ticket or waiting for a platform engineer to do it manually. It abstracts away the underlying complexity of Kubernetes namespaces, cloud IAM policies, and infrastructure provisioning into simple, safe, self-service operations.
Real-world examples of IDP tooling include Backstage (an open-source developer portal originally built at Spotify), Port, and Cortex. These provide service catalogues, golden path templates, and developer-facing dashboards that sit on top of the underlying infrastructure.
The critical property of a mature IDP is self-service. A developer should not need a human intermediary to create a namespace or spin up a test environment. They type a command or click a button, and the platform handles the rest. A platform team that requires manual involvement for routine operations is not yet delivering the value it is capable of, and it risks becoming a bottleneck rather than an accelerator.
Measuring Platform Team Impact: DORA Metrics
Platform teams often struggle to demonstrate their value to leadership in concrete terms. The DORA metrics — named after the DevOps Research and Assessment programme — provide a widely adopted framework for measuring software delivery performance, and they map directly onto what a healthy platform team should improve.
The four key DORA metrics are deployment frequency (how often code is deployed to production), lead time for changes (how long it takes from committing code to it running in production), change failure rate (what percentage of deployments cause incidents or require rollbacks), and time to restore service (how quickly a team can recover from an incident).
A well-functioning platform team drives improvements across all four of these. Shared CI/CD pipelines and golden paths increase deployment frequency and reduce lead time. Standardised deployment practices and pre-production validation reduce change failure rate. Uniform observability and runbooks reduce time to restore service. These are tangible, measurable outcomes that connect platform investment to business outcomes.
How Platform Teams Fail: The Common Pitfalls
Platform teams fail in predictable ways, and the warning signs are worth knowing before they become expensive to reverse.
Becoming a gatekeeper. When a platform team starts requiring approval tickets, design reviews, and manual sign-offs for routine operations, it transforms from an enabler into a bottleneck. A change that should take ten minutes ends up taking two weeks. The operational velocity that motivated the microservices adoption disappears, just from a different source. A useful diagnostic: if developers are filing tickets to request routine infrastructure actions — a new namespace, a database, an environment variable — the platform team is already failing at self-service. That friction is not a minor inconvenience; it is the earliest and most reliable signal that the team has become a dependency rather than a foundation.
Overly opinionated systems. When a platform team falls in love with a specific approach and mandates it across all teams regardless of context, it creates friction for legitimate edge cases. Some services are long-running HTTP APIs. Others are batch jobs. Others are event-driven consumers. A deployment pattern that works well for one may be poorly suited to another. The platform should provide strong defaults, not rigid mandates.
The framework monolith. One of the most damaging failure modes is building a massive internal framework that every service must import. It handles authentication, logging, tracing, configuration, and more — all in one mandatory package. Initially it seems convenient. Over time it becomes impossible to evolve without breaking every service that depends on it. Upgrading the framework requires coordinating across every team simultaneously. It is the monolith recreated inside a shared library, and it introduces exactly the build-time coupling that was described earlier — the distributed monolith via dependency graph. The services remain independently deployable on paper, but they are now coupled at the dependency level in a way that is often harder to untangle than the original monolith was.
Forcing adoption through policy rather than quality. The most effective platform teams make the paved road so clearly better than the alternatives that teams choose it voluntarily. When teams have to be compelled by governance policy or failing CI checks, it is a signal that the platform has not yet earned trust. Mandated adoption creates resentment; earned adoption creates momentum.
Neglecting versioning and deprecation. As the platform evolves, older interfaces and patterns need to be retired. Doing this without a clear deprecation process forces teams into disruptive migrations on no notice. A healthy platform team versions its APIs and tooling, communicates deprecation timelines transparently, and provides migration paths rather than simply cutting support.
When a platform team goes wrong, the symptom is consistent: developers route around the platform or actively push back on using it. A platform that slows teams down is just a centralised dependency layer with a better name.
When Not to Build a Platform Team
Platform teams are not appropriate at every stage of an organisation's growth. Building one too early is a waste of engineering capacity and creates coordination overhead that serves no one.
With only a handful of services — say, fewer than five or six — duplication is annoying but manageable. The patterns have not repeated enough times to know what is worth standardising. Building platform infrastructure at this stage risks locking in architectural decisions before enough is known about the domain.
If the architecture is still in flux — teams are still exploring whether to use gRPC or REST, Kafka or a simpler queue, Kubernetes or serverless functions — any platform built around those choices will either constrain future decisions or require constant rebuilding. The right time to standardise is after the major choices have stabilised.
If ownership of infrastructure is politically contested — no agreement on who is responsible for the deployment pipeline or the observability stack — a platform team will spend its time in alignment meetings rather than building useful tooling.
A simple principle applies here: do not platform what has not yet been standardised. Let the duplication emerge. Let the pain accumulate in specific, visible ways. Notice the patterns. Then build the platform around the problems that are actually hurting people, not the problems that might hurt them someday.
If no repeated pain patterns are visible yet, what is needed is good documentation and possibly a shared library. A platform team at this stage solves problems that do not exist and creates overhead that slows everything down.
There is also a middle path: shared infrastructure responsibilities distributed across teams, with no dedicated platform team. This can work well in organisations with strong devops culture and engineers who are comfortable owning infrastructure outside their immediate domain. It is not that a platform team is always necessary. It is that when the pain of distributed ownership exceeds the cost of dedicated headcount, a platform team becomes a worthwhile trade-off.
How to Build a Platform Team That Actually Works
The most important mental shift for a platform team is this: treat internal developers as customers. This sounds simple but changes everything about how the team operates.
It means talking to developers regularly to understand their actual pain points rather than building what seems architecturally elegant. It means measuring success by developer velocity — how long it takes to go from "we need a new service" to "the service is running in production with logs and dashboards" — not by the sophistication of the infrastructure. It means running a proper product backlog with prioritised work based on developer impact, not infrastructure preferences.
It means saying no to features that are clever but do not solve real problems. It means retiring old tools when better ones exist, even if it creates short-term migration work.
The practical approach breaks down into a few specific practices:
Build paved roads, not walls. The golden path should be obviously better than the alternatives — not because alternatives are prohibited, but because the paved path saves time, reduces errors, and comes with support. If a team has a legitimate reason to deviate, they should be able to do so with some deliberate effort. The platform team's job is to make the right path easy, not to make every other path impossible.
Default to self-service. Every routine operation — provisioning a service, requesting infrastructure, configuring an alert — should be available without human intermediation. If a developer has to wait for a platform engineer to perform a routine task, that is a product gap.
Reduce cognitive load, not just code duplication. The goal is not just to eliminate duplicated code. The goal is to eliminate the mental overhead of distributed infrastructure. Every decision a developer no longer has to make — because the platform has made it once, correctly — is a decision they can spend on their users.
Ship continuously. The worst platform teams spend months on a "platform v2" that breaks everything on release. The best platform teams ship something useful every week, even if it is a small improvement to documentation, a new template, or a minor quality-of-life improvement to the CLI. Small, frequent improvements compound into a platform that developers actually trust.
Measure and share the outcomes. Track DORA metrics before and after platform investments. Share the results. When the lead time for new service creation drops from three weeks to two hours, that story is worth telling explicitly — because the value of platform work is often invisible when it is working correctly.
The Autonomy vs Standardisation Balance
There is an inherent tension at the heart of platform engineering, and it does not fully resolve — it is managed.
Too much standardisation creates bottlenecks, resentment, and a platform team that has become a centralised command-and-control structure wearing the name of a platform. Too much autonomy recreates the duplication problem, diverging implementations, and the operational chaos that motivated the platform investment.
The productive resolution is to be explicit about what belongs in each category.
Standardise the foundations: the wire protocol, the logging format, the deployment pipeline structure, the authentication mechanism, the observability schema. These are the grammar of the distributed system. They need to be consistent so that services can communicate reliably and engineers can debug across service boundaries.
Leave everything else to the product teams: the domain model, the database schema, the API design, the internal algorithms, the technology choices within those constraints. That is where autonomy lives, and where the value the company actually sells is created.
A useful mental model is three layers. At the bottom, raw infrastructure: cloud providers, Kubernetes clusters, networking. At the top, the product layer: business logic, domain models, user-facing features. In the middle, the platform layer: self-service tooling, deployment pipelines, observability systems, shared libraries. The platform layer mediates between the inflexible bottom and the flexible top. It absorbs the complexity of infrastructure and turns it into a calm, repeatable foundation that product teams can stand on without needing to understand the details underneath.
The teams at the top standardise the language. They leave the novels entirely to the authors.
This maps directly back to the golden rule stated earlier: standardise interfaces, not implementations. The wire protocol is an interface. The logging schema is an interface. The health check contract is an interface. What sits behind each of those — the code, the libraries, the internal data model — belongs to the team.
Platform Maturity: The Typical Progression
Organisations that get platform engineering right tend to pass through recognisable stages. Understanding the progression helps teams know where they are and what to work toward next.
Operational chaos. No standards. Each service is built and operated differently. The overhead is high, but everyone is too busy fighting production fires to address root causes.
Accidental duplication. Teams begin noticing they are solving the same problems independently. Informal sharing begins — Slack messages, wiki pages, copied snippets.
Shared libraries as a partial solution. A common code repository emerges. This reduces some duplication but leaves operational inconsistencies untouched.
Emerging platform team. A small group — often senior engineers who have felt the pain most acutely — begins building real tooling: service templates, shared pipelines, observability standards. This group may operate informally at first.
Dedicated platform team. The group receives official recognition, headcount, and a product mandate. A product manager joins. A backlog exists. The team starts operating with the discipline of a product team rather than an internal infrastructure function.
Internal Developer Platform maturity. Self-service is the default. Developer onboarding to a new service takes hours. The platform is treated as a first-class product with user research, release cycles, and defined success metrics.
Product-like engineering ecosystem. The platform is mature enough that its existence is largely invisible. Teams think about their users and their business logic. The foundation is simply there — reliable, consistent, and maintained.
Most organisations stall somewhere between the emerging platform team and the dedicated platform team. The leap from informal side-project to fully funded product team is the hardest transition, because it requires organisational commitment to something whose value is difficult to see precisely because it is working.
Summary
A platform team solves the infrastructure duplication problem that emerges as microservices scale. It is not a Centre of Excellence — it builds and operates production systems, not documentation. It is not a shared library — it owns the runtime environment and operational consistency, not just code.
An Internal Developer Platform is the product a platform team builds. Self-service is its most important property.
Build a platform team only when repeated pain patterns are visible. Avoid building one when services are few, architecture is unstable, or organisational ownership is unclear. Let the duplication emerge, then standardise around the problems that are actually hurting teams.
Measure the impact using DORA metrics: deployment frequency, lead time, change failure rate, and time to restore service. These connect platform investment to outcomes that matter to the business.
The balance between autonomy and standardisation is the enduring tension of the discipline. Standardise the foundations. Leave business logic flexible. Build paved roads, not walls. And apply the golden rule consistently: standardise interfaces, not implementations. Shared libraries and mandatory frameworks that create compile-time coupling across services are not standardisation — they are a distributed monolith by another name.
And the most reliable sign that a platform team is working: developers stop noticing it exists, because the foundation never breaks.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.